

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the problem of pairing socks from an array that contains  pairs of socks.
pairs of socks.
First, we’ll define the problem and provide an example that explains it.
Second, we’ll present a naive approach. Then we’ll discuss two different approaches to improve it, and obtain better solutions.
Suppose we have pairs of socks randomly distributed inside an array of length  . Each sock may have one or more specifications, such as size, color, etc; therefore, we have to pair each sock with another of the same specifications.
. Each sock may have one or more specifications, such as size, color, etc; therefore, we have to pair each sock with another of the same specifications.
To understand this more clearly, let’s look at a simple example.
Let’s say that we have an array with  socks. Additionally, each sock has a special color and a special size:
socks. Additionally, each sock has a special color and a special size:

Now suppose that the color of each cell represents the color of the corresponding sock, while the number written inside the cell represents the sock size. Consequently, we can find the solution to pairing the socks:
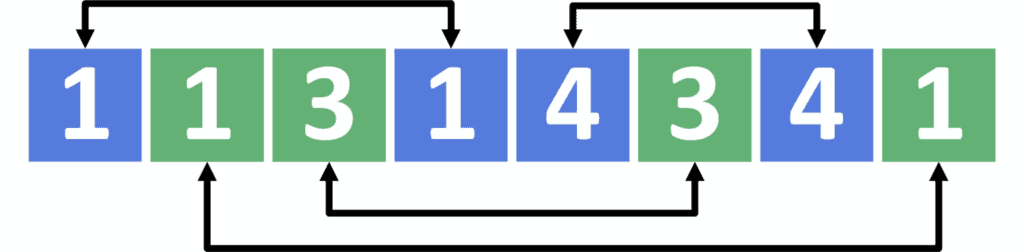
Note that in this tutorial, we’ll discuss finding only one possible solution; we won’t consider the case where we might have more than one answer.
The main idea here is to iterate over the socks. For each sock, we’ll try to find a similar one that hasn’t been paired before.
Let’s take a look at the implementation:
algorithm findSimilarPairsNaive(N, sock):
// INPUT
// N = the number of pairs of socks
// sock = the array that represents the socks
// OUTPUT
// Returns similar pairs of socks in sock
answer <- an empty sequence
taken <- an array of false, with length 2 * N
for i <- 0 to 2 * N - 1:
if taken[i] is true:
continue
taken[i] <- true
for j <- i + 1 to 2 * N - 1:
if sock[i] = sock[j]:
answer <- add (sock[i], sock[j]) to answer
taken[j] <- true
break
return answerInitially, we declare a list called  , which will store the result as pairs of socks. In addition, we declare an array called
, which will store the result as pairs of socks. In addition, we declare an array called  , which expresses whether each sock has been taken before or not. Furthermore, we initialize this array with
, which expresses whether each sock has been taken before or not. Furthermore, we initialize this array with  values.
values.
Next we iterate over the socks. If the sock hasn’t been taken before, we try to find a similar one by iterating over the remaining socks and checking for similarities. If a match is found, we add the similar socks to , and flag both of them as taken.
Finally, we return , which stores the similar pairs of socks in the given array.
The time complexity here is  . Let’s examine the reason behind this complexity.
. Let’s examine the reason behind this complexity.
To start, we iterate over all the socks. For each one, we iterate over all the socks located after it inside the array. We’ll find that the  sock will iterate over
sock will iterate over  socks because no socks come after it. Similarly, the
socks because no socks come after it. Similarly, the  sock will iterate over
sock will iterate over  sock, and so on. As a result, this step will cost
sock, and so on. As a result, this step will cost  , which equals
, which equals  .
.
The main idea here is to sort the array of socks first. When we sort it, similar socks will be next to each other; therefore, we only have to iterate over the sorted array and check each sock with its adjacent.
Let’s take a look at the implementation:
algorithm findSimilarPairsSorting(N, sock):
// INPUT
// N = the number of pairs of socks
// sock = the array that represents the socks
// OUTPUT
// Returns similar pairs of socks in sock
answer <- an empty sequence
sorted <- sort(sock)
i <- 0
while i <= 2 * N - 2:
if sorted[i] = sorted[i + 1]:
answer <- add (sorted[i], sorted[i + 1]) to answer
i <- i + 1
i <- i + 1
return answerInitially, we declare a list called , which will store the result as pairs of socks. Then we sort the given array and store it in  .
.
Next we iterate over the socks, and check the similarity between the  sock and the
sock and the  one. If they are similar, we add the similar socks to , and increase the iterator
one. If they are similar, we add the similar socks to , and increase the iterator  by to prevent the sock from joining more than one pair.
by to prevent the sock from joining more than one pair.
Finally, we return , which stores the similar pairs of socks in the given array.
The time complexity here is  . Let’s examine the reason behind this complexity.
. Let’s examine the reason behind this complexity.
The main complexity of this approach is the sorting algorithm, so we prefer to choose an algorithm with  complexity as merge sort.
complexity as merge sort.
Then we iterate over all the socks once, and we only need  to do that.
to do that.
The main idea here is to use a HashSet to store the last appearance of a similar sock. Consequently, we iterate over the socks, and in each step, we check whether the HashSet contains a similar sock or not.
Let’s take a look at the implementation:
algorithm findSimilarPairsHash(N, sock):
// INPUT
// N = the Number of pairs of socks
// sock = the array that represents the socks
// OUTPUT
// Returns similar pairs of socks in sock
answer <- an empty sequence
hash_set <- create an empty hash set
i <- 0
while i < 2 * N:
if hash_set contains sock[i]:
answer <- add (sock[i], hash_set.get(sock[i])) to answer
hash_set.delete(sock[i])
else:
hash_set.add(sock[i])
i <- i + 1
return answerInitially, we declare a list called , which will store the result as pairs of socks. We also declare  as an empty HashSet.
as an empty HashSet.
Then we iterate over the socks, and check whether contains a similar sock to the one. If it does, we add both the sock and the similar sock from to the result. In addition, we delete the similar one to prevent the sock from joining more than one pair. If the HashSet doesn’t contain a similar sock, we add the sock to .
Finally, we return , which stores the similar pairs of socks in the given array.
The time complexity here is  .
.
First, we iterate over all the socks once, and we only need to do that. At each step, we check if contains a special sock, which has a  complexity. Also, the operation of adding and deleting from has a complexity.
complexity. Also, the operation of adding and deleting from has a complexity.
In this article, we presented the problem of pairing socks. We also explained the main ideas behind three different approaches to solving this problem, and walked through their implementations.