

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about gradient-based algorithms in optimization. First, we’ll make an introduction to the field of optimization. Then, we’ll define the derivative of a function and the most common gradient-based algorithm, gradient descent. Finally, we’ll also extend the algorithm to multiple input optimization.
The goal of an optimization algorithm is to find the input value  that minimizes or maximizes the output value of a function
that minimizes or maximizes the output value of a function  .
.
We usually work only with minimization algorithms since a maximization problem of  can be transformed into a minimization problem of
can be transformed into a minimization problem of  . So, from now on, we’ll talk only about minimization problems.
. So, from now on, we’ll talk only about minimization problems.
Formally, we usually refer to the function that we want to minimize as an objective function or loss function.
An example of a simple minimization problem is the Linear Least Squares, where we want to approximate a linear function given some sample data. In this case, the objective function is defined as:

Moreover, we have the minimum value denoted as:

An essential part of every gradient-based algorithm is the gradient, as the name suggests. First, we’ll focus on the case of a single input  where the gradient of a function is defined as the derivative
where the gradient of a function is defined as the derivative  or
or  .
.
Geometrically, the derivative of a function at point corresponds to the function’s slope at this point. This concept is illustrated in the below diagram:
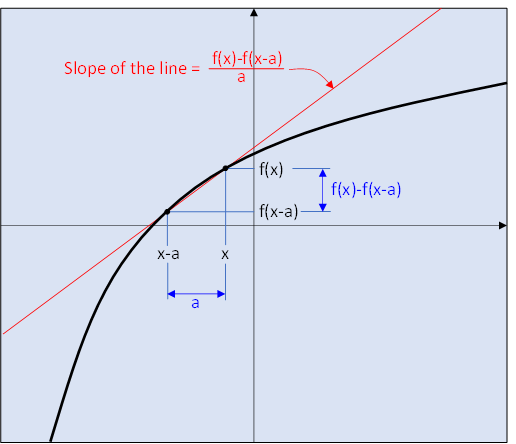
To put it more simply, the gradient specifies how a small change in input will affect the output.
Gradient descent is a very famous gradient-based algorithm first proposed by Augustin-Louis Cauchy.
It is based on a very simple observation:
The value of  is less than for small changes in
is less than for small changes in  . So, we can reduce the value of an objective function by changing the input to the opposite sign of the computed derivative.
. So, we can reduce the value of an objective function by changing the input to the opposite sign of the computed derivative.
Now, let’s present an example to illustrate better how gradient descent works. We suppose that we want to minimize the function:

with derivative

We aim to find the global minimum of that holds when  . So, we start at a random input value of
. So, we start at a random input value of  :
:
 it means that
it means that  and we can decrease the value of
and we can decrease the value of  be moving leftward. This is equivalent to reducing the value of by a value
be moving leftward. This is equivalent to reducing the value of by a value  it means that
it means that  and we can decrease the value of be moving rightward. This is equivalent to increasing the value of by a value
and we can decrease the value of be moving rightward. This is equivalent to increasing the value of by a value The diagram below shows the whole procedure:
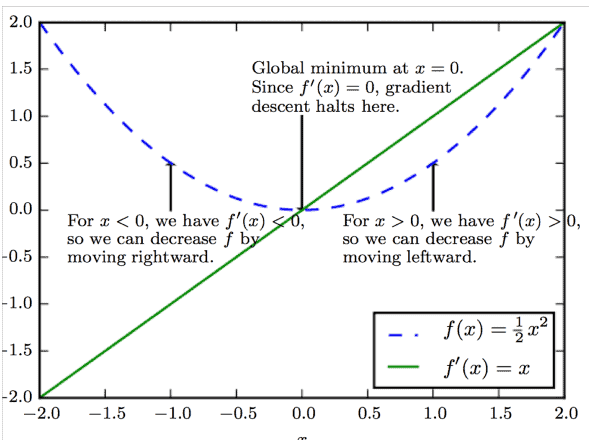
We stop the procedure when after some iterations, the change in the value of will be less than a predefined small threshold, meaning we have reached the minimum of the function.
In case of multiple inputs ( ), we have to use partial derivatives
), we have to use partial derivatives  that measures how the function
that measures how the function  changes as only one of its inputs
changes as only one of its inputs  changes. In this case, the gradient is a vector that contains the partial derivatives of the function and is denoted as
changes. In this case, the gradient is a vector that contains the partial derivatives of the function and is denoted as  .
.
Suppose we generalize the method of gradient descent that we mentioned for the case of multiple inputs. In that case, we observe that the positive gradient points directly uphill, and the negative gradient points directly downhill. So, we can decrease the value of by moving in the direction of the negative gradient.
In this article, we talked about gradient-based algorithms in optimization. First, we introduced the important field of optimization and talked about a function’s derivative. Then, we presented the gradient descent algorithm, which is the most common gradient-based algorithm. Finally, we generalized the algorithm for the case of multiple inputs.