

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll introduce the concept of offline concurrency control, and discuss the advantages and drawbacks of approaches: pessimistic and optimistic offline locking.
When we design applications, we usually need to facilitate some level of concurrent access to shared data. This calls for measures to protect data integrity, and to avoid common problems such as lost updates and inconsistent reads.
Lost updates occur when a process performs an update on data that has been changed by another process since its last retrieval. The previous changes are then written over:
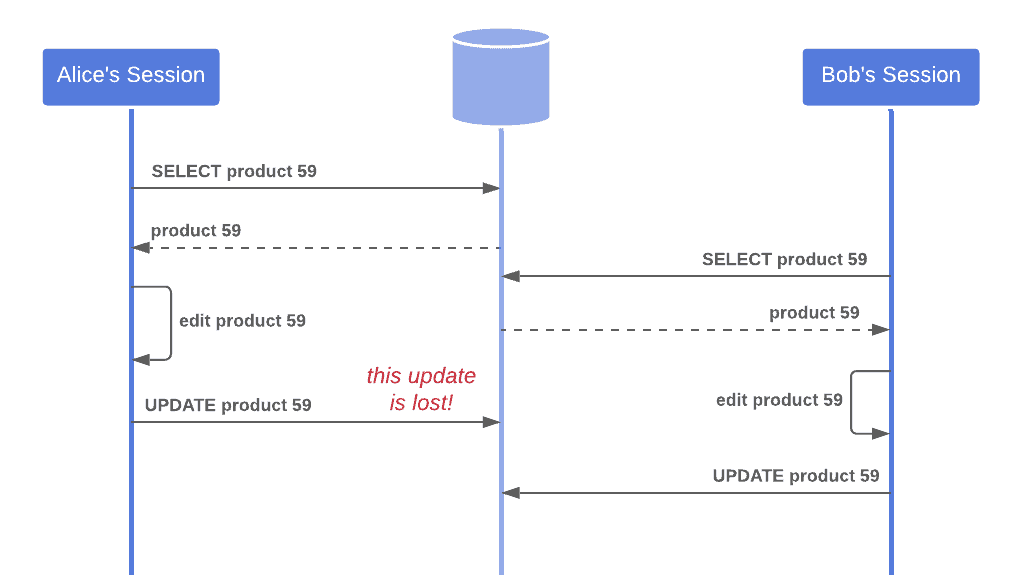
An example of inconsistent reads is if a process reads data that is partway through being updated by another process. If we then use this data in some meaningful way, we may run into issues:
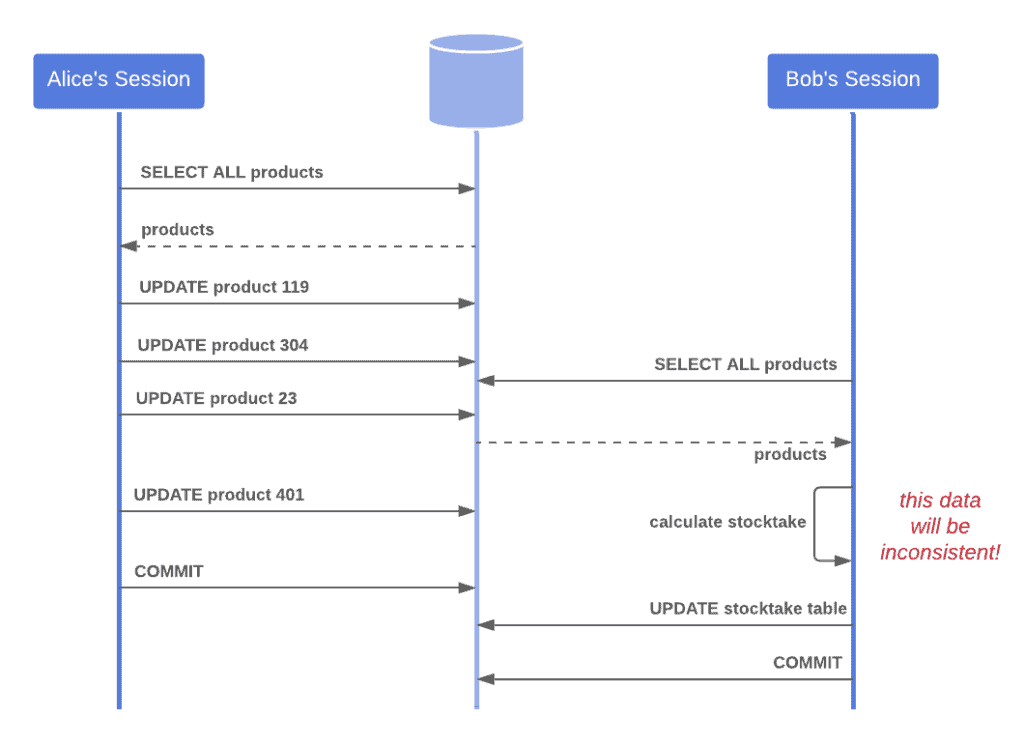
Often, the underlying resource – e.g. the database – handles safe concurrent access for individual database transactions.
However, such a resource knows nothing beyond the scope of its individual database transactions, and we might need to perform business transactions that involve several transactions with the database:
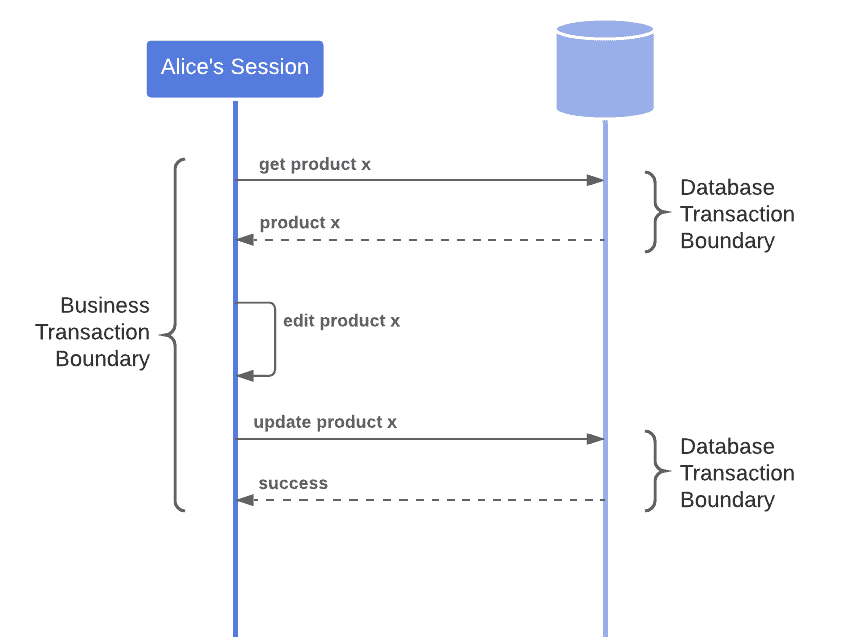
In these cases, we need to consider a higher-level strategy to handle concurrency, such as offline concurrency control.
Offline concurrency control is a strategy that handles concurrent access to data for business transactions that might span across multiple database transactions.
Today, we’ll introduce two approaches: optimistic and pessimistic offline locking.
Optimistic offline locking is a technique that detects when there is a conflict between two concurrent business transactions and performs a rollback accordingly.
Essentially, it checks whether a business transaction has the most up-to-date version of data before committing a transaction. If it doesn’t, we abandon the transaction and rollback any changes up to this point.
This prevents the problem of lost updates – we won’t allow a business transaction to update data if this data has changed since its last retrieval.
However, it doesn’t solve the problem of inconsistent reads, and it also means that whenever a conflict occurs, the abandoned process will lose its work. This isn’t ideal if conflicts are expected to occur often or if the impact of abandoning a business transaction is significant.
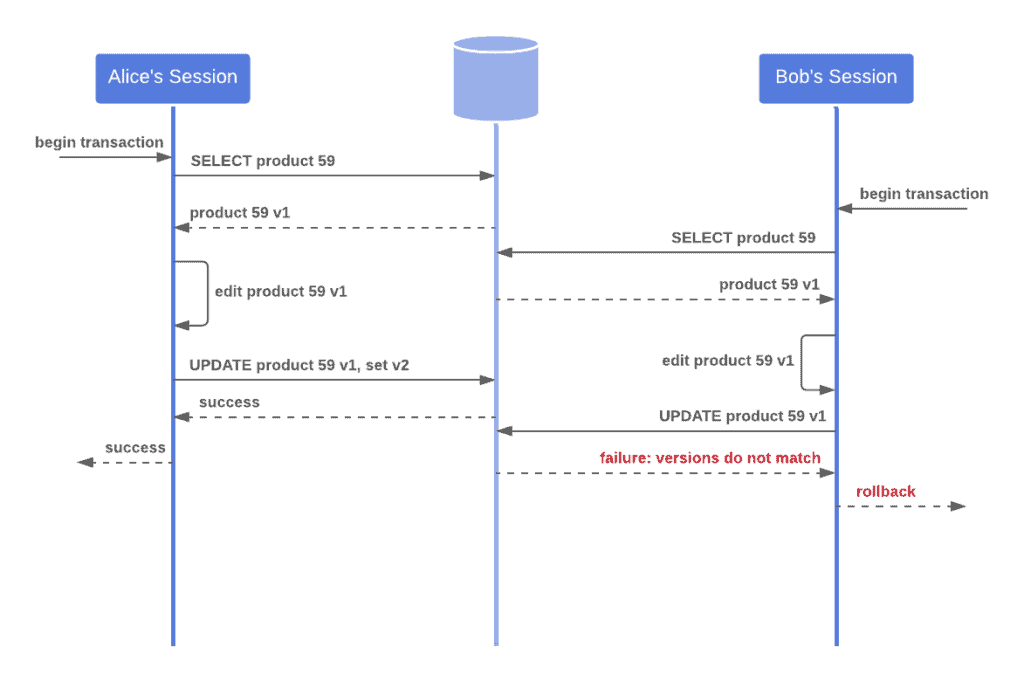
A common approach is to associate a version number with each record in the database. Then, when we read a record, we store its version alongside it, for example in session state.
After changes are made and before writing the record back to the database, we again retrieve the version number from the database and check if it matches what we have.
If it does, then we can safely write the data back. We obtain a lock on the rows we wish to update and write the new data to the database, making sure we update the version number of each changed record.
If it doesn’t, then our data must be stale – another process has changed it since our last retrieval. So we simply fail the transaction.
Here’s a visual representation of this process:
To get some additional details, please check our example implementation of optimistic offline locking using JPA and Hibernate.
As we have seen, this approach is fairly straightforward to implement.
It also promotes good liveliness – records are locked for a short time during a commit, but processes are otherwise free to access data at the same time.
A trade-off here, however, is that whenever we detect a conflict, the business transaction acting on stale data will lose any work up until that point. Since conflicts are only detected at the eleventh hour, this might cause a great deal of frustration for the user.
So, we should use this technique if we prioritize liveliness in our system and ease of implementation.
We should avoid this technique if our business transactions contain a number of steps that would be undesirable to have to repeat.
The basic idea here is that each process must obtain a lock on the shared data at the start of a business transaction. So, rather than waiting until the end of the transaction to determine that a conflict has occurred, we prevent the conflict from happening in the first place.
If one user starts a business transaction that will access some shared data, no other user can attempt the same action. This means that, when it comes time to write data back to the database, we know there won’t be any conflict – so no one will lose work.
This strategy is a fair bit more complex than its optimistic counterpart. Before we can implement it, we need to make a few decisions.
Firstly, we must decide what sort of lock we’ll use:
We also need a lock manager: some mechanism that handles the acquisition and release of locks and keeps track of which processes have which locks. This may take many forms, such as a server-side data structure or an additional database table.
Here’s an example of how this technique might be used:
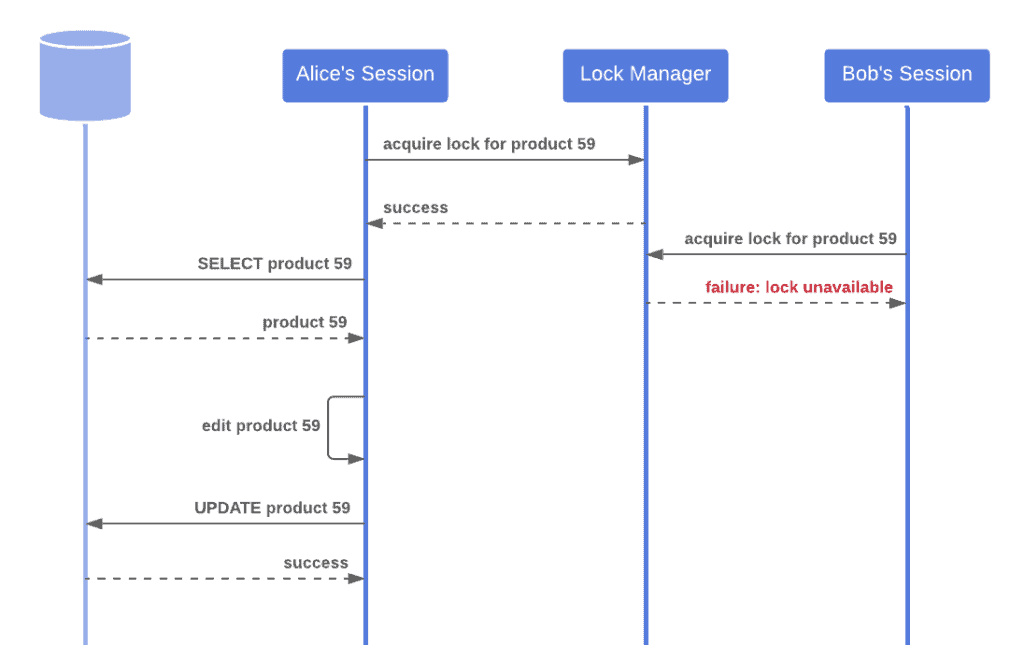
To see this technique in action, check out pessimistic locking using JPA and Hibernate.
Avoiding lost work is one major advantage of this approach. If a business transaction requires multiple steps, then failing a process at the beginning of a transaction rather than the end may save considerable user frustration. Pessimistic offline locking also prevents lost updates and protects against inconsistent reads when a “read” or “read/write” lock is chosen.
A significant drawback of this strategy, however, is its impact on liveliness. Naturally, by making access to a resource exclusive, we’ll force some users to wait. This may be detrimental to the system’s goals if users frequently access the restricted resource.
Also, as we have seen, pessimistic offline locking can be complex to implement.
So, it’s likely to be worthwhile only if conflicts between processes are likely to be frequent, or the cost of these conflicts is high.
Today, we introduced a useful tool for handling concurrent data access across multiple database transactions. We discussed how optimistic offline locking generally favors liveliness within the system over data integrity, whilst pessimistic offline locking favors the opposite.