

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn how different dimensions are used in convolutional neural networks.
To better grasp these concepts, we’ll illustrate the theory with a few cases from real life. Let’s begin!
Convolutional Neural Networks (CNNs) are neural networks whose layers are transformed using convolutions.
A convolution requires a kernel, which is a matrix that moves over the input data and performs the dot product with the overlapping input region, obtaining an activation value for every region.
A kernel represents a pattern, and the activation represents how well the overlapping region matches that pattern:
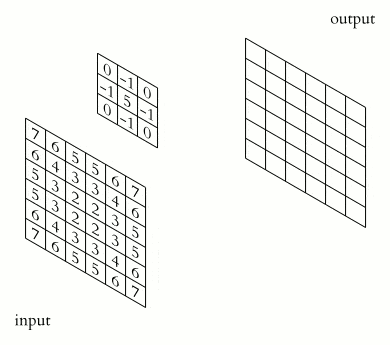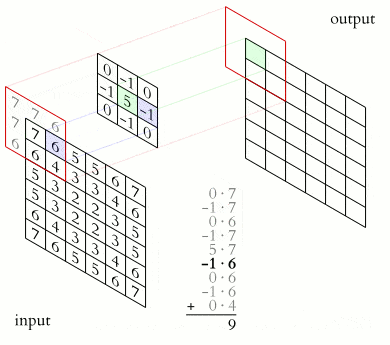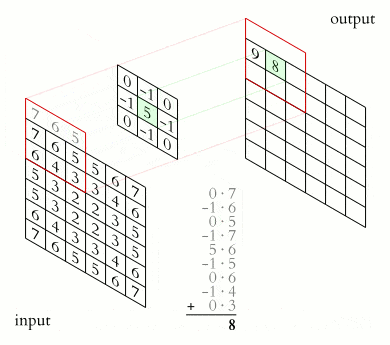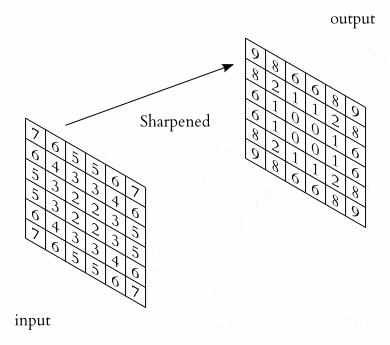
The objects affected by dimensions in convolutional neural networks are:
For 1D input layers, our only choice is:
A 1D layer is just a list of values, which we can represent with a graph:
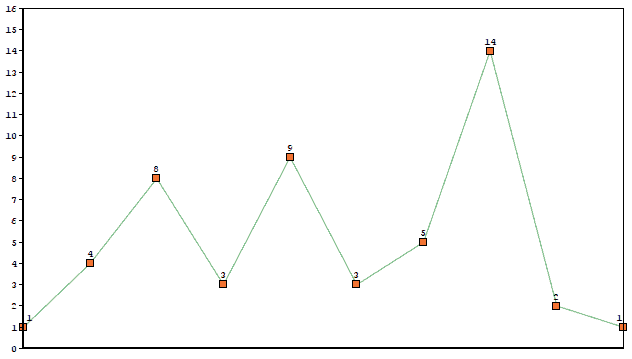
The kernel will slide along the list producing a new 1D layer.
Imagine we used kernel [0.33, 0.67, 0.33] on the previous graph. The output would be:
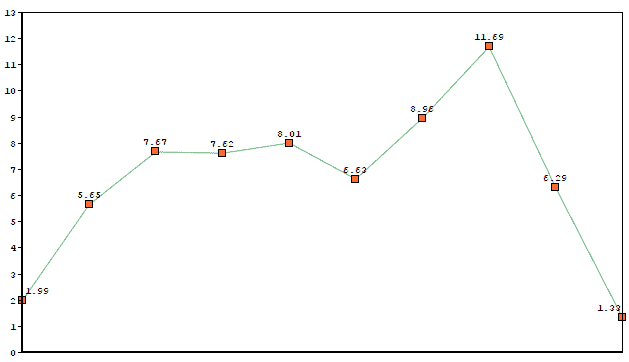
As we see, it still preserves some of the original shape, but now it’s a lot smoother.
Let’s start with the dimensions:
This is perhaps the most common example of convolution, where we’re able to capture 2D patterns in images, with increasing complexity as we go deeper in the network:

Above we see the kind of patterns a face detection network is able to capture: Earlier layers (left picture) are able to match simple patterns like edges and basic shapes. Middle layers (center picture) find parts of faces like noses, ears, and eyes. Deeper layers (right picture) are able to capture different patterns of faces.
In Natural Language Processing, we often represent words with numeric vectors of size  , and
, and  -gram patterns with
-gram patterns with  kernels. Each activation represents how well those words match the -gram pattern.
kernels. Each activation represents how well those words match the -gram pattern.
Let’s see the dimensions:
Now imagine that we used a kernel encoding the meaning of “very wealthy”. Most similar words in meaning will have higher activation:
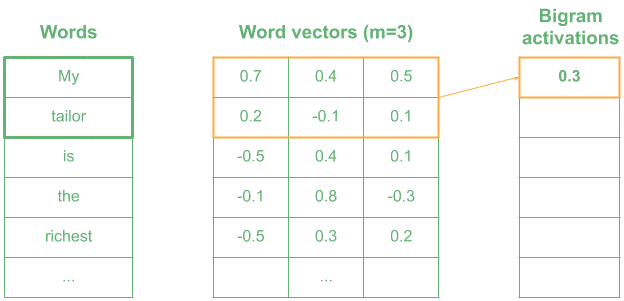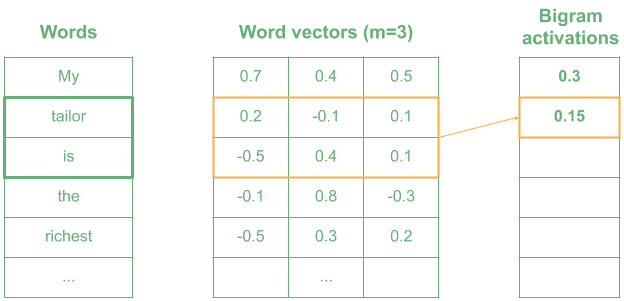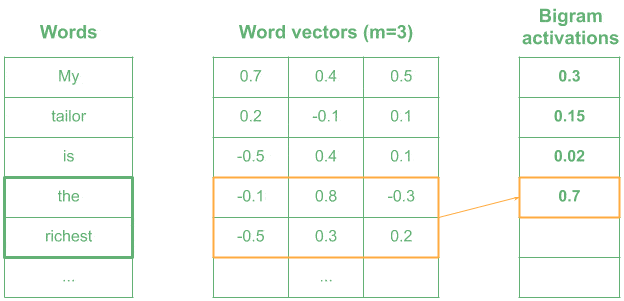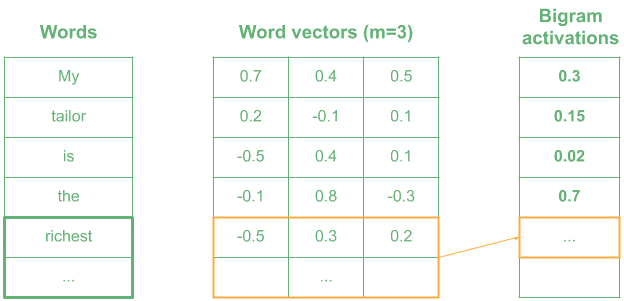
In the example, words like “the richest” produce a high value, as they are similar in meaning to “very wealthy”, whereas words like “is the” return a lower activation.
Let’s see what happens when kernel depth < input depth.
Our dimensions are:
Each 3D kernel is applied over the whole volume, obtaining a new 3D layer:
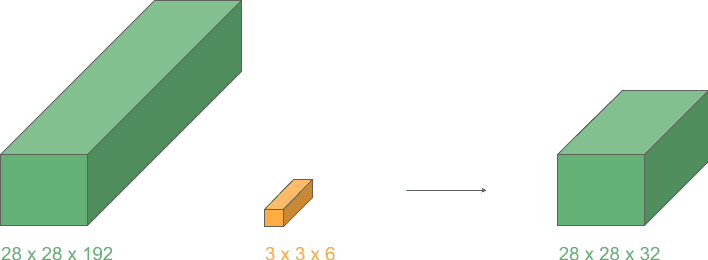
These convolutions can be used to find tumors in 3D images of the brain, or video events detection, for example.
Now let’s consider the case when kernel depth = input depth.
In that case, our dimensions will be:
We’ll apply a 3D kernel to a 3D volume in just 2 dimensions because depths match. Et voilá! Now we have a new layer with the same height and width but with one less dimension (from 3D to 2D):
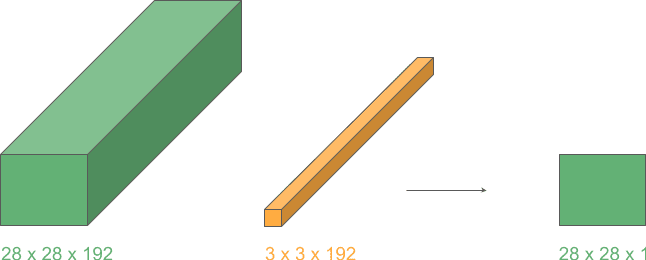
This operation lets us transition between layers of different dimensions and is very often used with height and width 1 for greater efficiency, as we’ll see in the next example.
Finally, we’ll take advantage of what we learned in the previous case to create a cool reduction effect.
These are the dimensions:
From the previous example, we know that applying a 2D convolution to a 3D input where depths match will produce a 2D layer.
Now, if we repeat this operation for kernels, we can stack the output layers and obtain a 3D volume with the reduced depth, .
Let’s see an example of a depth reduction from 192 to 32:
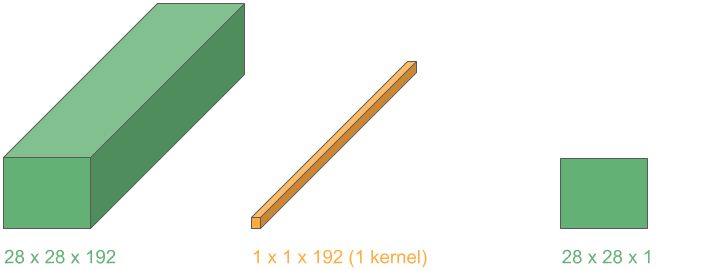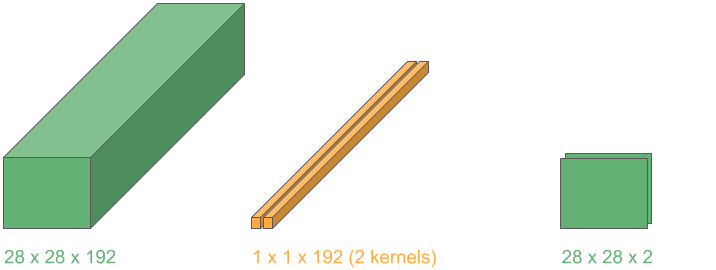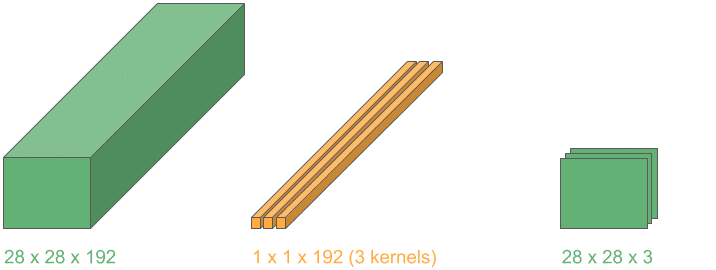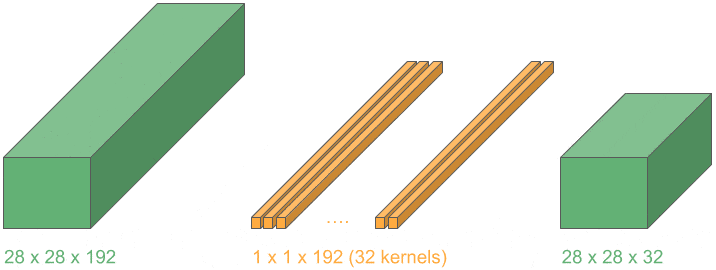
This operation lets us shrink the number of channels in the input, in contrast to typical convolutions where just height and width get reduced. They are widely used in the very popular Google network “Inception”.
In this article, we’ve seen the effect of using different dimensions in convolutional objects, and how they are used for different purposes in real life.