
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn different ways to compute the Levenshtein distance between two strings. Additionally, we’ll explore the complexity of basic implementations and discuss methods for improving them.
But before we do that, let’s refresh some basics about the Levenshtein distance.
Levenshtein distance is the smallest number of edit operations required to transform one string into another. Edit operations include insertions, deletions, and substitutions.
In the following example, we need to perform 5 operations to transform the word INTENTION into EXECUTION. Therefore, the Levenshtein distance between these two words is 5:
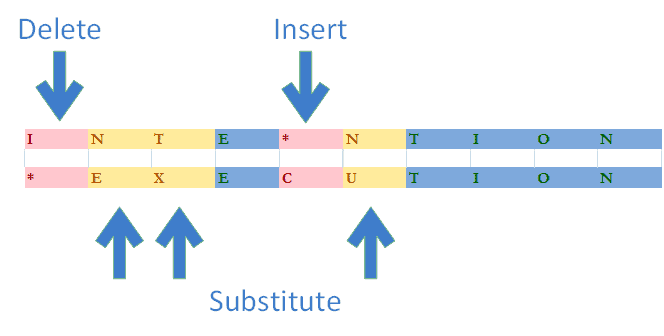
Levenshtein distance is the most popular metric among the family of distance metrics known as edit distance. These sibling distance metrics differ in the set of elementary operations allowed to execute the transformation. For example, Hamming distance permits substitutions only. On the other hand, the Damerau-Levenshtein distance allows character transpositions in addition to the set defined by the Levenshtein distance. Thus, it’s commonly used instead of classical Levenshtein distance under the same name.
In classical Levenshtein distance, every operation has a unit cost. Additionally, specialized versions may assign different costs to operations. Furthermore, the cost may also depend on the character. Here, we want to define a complex operation cost function to represent character visual or phonetic similarity.
The Levenshtein distance between two strings  is given by
is given by  where
where

In this equation,  is the indicator function equal to 0 if
is the indicator function equal to 0 if  and 1 otherwise. By
and 1 otherwise. By  , we denote the length of the string
, we denote the length of the string  .
.
Furthermore,  is the distance between string prefixes – the first
is the distance between string prefixes – the first  characters of and the first
characters of and the first  characters of
characters of  .
.
In this example, the first part of this formula denotes the number of insertion or deletion steps to transform a prefix into an empty string or vice versa.
Moreover, the second block is a recursive expression. The first line represents deletion, and the second one represents insertion. Finally, the last line is responsible for substitutions.
The Levenshtein distance has the following properties:





These properties are useful for understanding how computation algorithms work and employing them in our applications.
In particular, the triangle inequality property can benefit specific tasks since building Metric Space is a major requirement. Metric Space, in turn, can be efficiently indexed with Metric Tree structures. These include, among others, BK-trees and VP-trees.
Now that we know Levenshtein distance’s theory and basic properties, let’s examine the methods to compute it. We’ll start with the most trivial and inefficient algorithm. Further, we’ll consider the options for improving it.
Every algorithm defined below uses zero-based string indexing.
Using the definition, we may write a straightforward recursive algorithm:
algorithm LevDist(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between strings a and b
if a.size() = 0:
return b.size()
if b.size() = 0:
return a.size()
if a[0] != b[0]:
indicator <- 1
else:
indicator <- 0
return min(
LevDist(a[1:], b) + 1, // deletion
LevDist(b[1:], a) + 1, // insertion
LevDist(a[1:], b[1:]) + indicator // substitution
)In this algorithm, the  function returns a substring of
function returns a substring of  starting at element
starting at element  .
.
Furthermore, this implementation recomputes distance for the very same prefixes multiple times. Thus, it’s very inefficient.
Due to the properties of the Levenshtein distance, we may observe that it’s possible to construct the matrix of size ![(|a| + 1) \times (|b| +1 ])](/wp-content/ql-cache/quicklatex.com-dd7fd5b51b1da082b6b69c0a19959a8f_l3.svg "Rendered by QuickLaTeX.com") which will contain the value at the position
which will contain the value at the position  . Therefore, this matrix’s first row and the first column are defined as having the values in ranges
. Therefore, this matrix’s first row and the first column are defined as having the values in ranges  and
and  , respectively.
, respectively.
Now, using a dynamic programming approach, we may flood-fill this matrix to obtain the final bottom-right element as our resulting distance. This implementation is known as the Wagner–Fischer algorithm:
algorithm LevenshteinDistanceIterativeFullMatrix(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between a and b
n <- a.size()
m <- b.size()
for i <- 0 to n:
distance[i, 0] <- i
for j <- 0 to m:
distance[0, j] <- j
for j <- 1 to m:
for i <- 1 to n:
if a[i] != b[j]:
indicator <- 1
else:
indicator <- 0
distance[i, j] <- min(
distance[i - 1, j] + 1, // deletion
distance[i, j - 1] + 1, // insertion
distance[i - 1, j - 1] + indicator // substitution
)
return distance[n, m]Running this algorithm on our INTENTION to the EXECUTION transformation sample yields the result matrix for prefix distances:
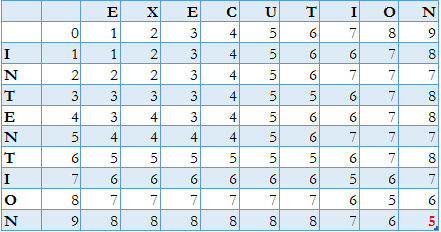
In particular, the bottom-right element of this matrix is exactly the 5 operations we observed previously.
To obtain the final value alone, we may easily modify the implementation above to avoid the entire matrix allocation. To move forward, we need only two rows: the one we’re currently updating and the previous one:
algorithm LevDistIterativeTwoRows(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// the Levenshtein distance between strings a and b
n <- a.size()
m <- b.size()
for j <- 0 to m:
previous[j] <- j
for i <- 0 to n - 1:
current[0] <- i + 1
for j <- 0 to m - 1:
if a[i] != b[j]:
indicator <- 1
else:
indicator <- 0
current[j + 1] <- min(
previous[j + 1] + 1, // deletion
current[j] + 1, // insertion
previous[j] + indicator // substitution
)
previous <- current // copy current row to previous row for next iteration
return previous[m] // result is in the previous row after the last swapHence, this optimization makes reading off the actual series of edit operations impossible. Hirschberg’s algorithm addresses this issue by using dynamic programming as well as the divide-and-conquer approach.
Furthermore, we may observe that we need only three values to calculate the value at a specific row position: the one to the left, the one directly above, and the last diagonal.
Thus, our function may be modified to allocate a single row and two variables instead of two. Therefore, this modification results in even more relaxed memory requirements:
algorithm LevenshteinDistanceIterativeSingleRow(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between strings a and b
n <- a.size()
m <- b.size()
for j <- 0 to m:
row[j] <- j
for i <- 0 to n - 1:
row[0] = i + 1
previousAbove <- row[0]
for j <- 0 to m - 1:
if a[i] != b[j]:
indicator <- 1
else:
indicator <- 0
previousDiagonal <- previousAbove
previousAbove <- row[j + 1]
row[j + 1] <- min(
previousAbove + 1, // deletion
row[j] + 1, // insertion
previousDiagonal + indicator // substitution
)
return row[m]The time complexity of all the iterative algorithms presented above is  . Additionally, space complexity for the full matrix implementation is , which usually makes it impractical to use. Moreover, both two-row and single-row implementations provide linear space complexity
. Additionally, space complexity for the full matrix implementation is , which usually makes it impractical to use. Moreover, both two-row and single-row implementations provide linear space complexity  . Additionally, swapping source and target to reduce computation row length will further reduce it to
. Additionally, swapping source and target to reduce computation row length will further reduce it to  .
.
It has been shown that the Levenshtein distance can’t be calculated in subquadratic time unless the strong exponential time hypothesis is false.
Fortunately, this applies to worst-case complexity only.
Therefore, we may introduce several optimizations that may prove essential for enabling distance calculation on the data sets for practical purposes.
Moreover, in our last single-row implementation, we’ve started investigating ways to reduce space allocation. Further, let’s see if we can further reduce the actual running time.
By looking at our INTENTION to the EXECUTION transformation example, we may notice that both of these words have the common suffix: TION. However, this suffix doesn’t affect the Levenshtein distance.
In particular, functions to obtain the first mismatch character position are usually very efficient. Thus, we may remove the longest common suffixes and prefixes to reduce the string portions to run through complete quadratic computation.
Therefore, the following implementation also includes the source and target swap mentioned above to provide space complexity mentioned above:
algorithm LevDistTweaked(a, b):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// OUTPUT
// The Levenshtein distance between the two strings, optimized by skipping common prefixes and suffixes
prefixLength <- mismatch(a, b)
a <- a[prefixLength:] // skip prefix
b <- b[prefixLength:] // skip prefix
suffixLength <- mismatch(a.reverse(), b.reverse())
a <- a[0: a.size() - suffixLength] // skip suffix
b <- b[0: b.size() - suffixLength] // skip suffix
if a.size() = 0:
return b.size()
if b.size() = 0:
return a.size()
if b.size() > a.size():
tmp <- a // swap to reduce space complexity
a <- b
b <- tmp
return LevDist(a, b) // run quadratic computationSuppose we have relatively long strings and are interested in comparing only similar strings, e.g., misspelled names. In such a case, complete Levenshtein computation would have to traverse the entire matrix, including the high values in the top-right and bottom-left corners, which we won’t always need.
Therefore, this gives us the idea of the possible optimization with the threshold, with all the distances above some boundary reported simply as out of range. Hence, for bounded distance, we need to compute only the values in the diagonal stripe of width  where
where  is the distance threshold.
is the distance threshold.
Let’s say we’re comparing strings SYDNEY MEIER and SYDNY MEYER with a threshold of 2. Thus, we need to compute the values of the cells in the stripe, which spans cells on either side of the diagonal cell, highlighted in red:
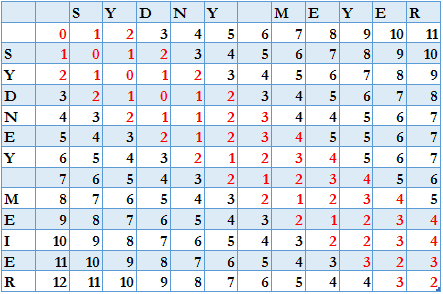
In other words, the implementation would give up if the Levenshtein distance is above the boundary.
Therefore, this approach gives us the time complexity of  , providing acceptable execution times for long but similar strings.
, providing acceptable execution times for long but similar strings.
Furthermore, as we know that the distance is at least the difference in length between the strings, we may skip the calculation if it exceeds the threshold we choose.
Now, we may implement the modification of Two Rows algorithm with the boundary:
algorithm LevDistBounded(a, b, k):
// INPUT
// a = the first string (0-indexed)
// b = the second string (0-indexed)
// k = the distance threshold
// OUTPUT
// The Levenshtein distance bounded by k, or -1 if the distance exceeds k
n <- a.size()
m <- b.size()
if abs(m - n) > k:
return -1
fillBound <- min(m, k)
for j <- 0 to fillBound:
previous[j] <- j
for j <- fillBound+1 to m:
previous[j] <- MAXINT
for j <- 0 to m
current[j] <- MAXINT
for i <- 0 to n-1:
current[0] <- i + 1
// compute stripe indices
stripeStart <- max(0, i - k)
stripeEnd <- min(m, i + k) - 1
// ignore entry left of leftmost
if stripeStart > 0:
current[stripeStart] <- MAXINT
// loop through stripe
for j <- stripeStart to stripeEnd:
if a[i] != b[j]:
indicator <- 1
else:
indicator <- 0
current[j + 1] <- min(
previous[j + 1] + 1, // deletion
current[j] + 1, // insertion
previous[j] + indicator // substitution
)
previous <- current
if previous[m] > k:
return -1
return previous[m]For practical purposes, we may first use this function to compute the distance with threshold 1. Then, we can double the threshold each time until the actual limit is reached or the distance is found.
Depending on our specific application, we may be happy with the results achieved by the optimization techniques listed above. However, since we may end up with quadratic computation, we must be aware of running time, especially in the case of long strings with low similarity.
Many metrics other than Levenshtein distance have linear running time: bag distance, Jaro-Winkler distance, or q-grams. We may use any of these techniques to filter out matches outside the acceptable similarity range. Once we have a small set of matches based on the approximate metric of choice, we may run real Levenshtein distance to rank those.
An alternative approach, which makes it possible to perform a fuzzy text search on a given dictionary, is to use Levenshtein Automaton. Here, the basic idea is that we may construct a Finite State Automaton for a string  and number
and number  that accepts exactly the set of strings whose Levenshtein distance from string is no more than .
that accepts exactly the set of strings whose Levenshtein distance from string is no more than .
By feeding any word into the constructed automaton, we may define if the distance from this word to the target string is larger than the specified threshold based on whether it was accepted or rejected by the automaton.
Due to the nature of FSAs, running time is linear with the length of the word being tested.
While automaton construction itself can be computationally very expensive, it has been shown that it’s possible in  .
.
The Levenshtein distance and its siblings from the family of edit distances find a wide range of applications.
Approximate string matching also referred to as fuzzy text search, is often implemented based on the Levenshtein distance. Furthermore, it’s used in a variety of applications such as spell checkers, correction systems for optical character recognition, speech recognition, spam filtering, record linkage, duplicate detection, natural language translation assistance, RNA/DNA sequencing in computational biology, and plagiarism detection, among others.
Several Java frameworks implement them in some form, including Hibernate Search, Solr, and Elasticsearch.
Finally, in linguistics, we may use Levenshtein distance to determine linguistic distance, the metric on how different the languages or dialects are from each other.
In this article, we’ve discussed different algorithms to implement the Levenshtein distance.
We’ve seen that the worst-case complexity is quadratic, and thus, the question of possible optimizations is crucial to our efforts to provide a usable implementation.
Finally, we observed that besides some techniques to reduce the computational cost directly, different approaches may be used to address the tasks on the agenda.