

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 16, 2023
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Hashing and encryption are the two most important and fundamental operations of a computer system. Both of these techniques change the raw data into a different format. Hashing on an input text provides a hash value, whereas encryption transforms the data into ciphertext.
Although both of these techniques convert the data into a separate format, there are subtle differences in their conversion mechanism and area of usage.
In this tutorial, we’ll discuss these techniques and their differences.
Hashing is the process of mapping any arbitrary size data into a fixed-length value using a hash function. This fixed-length value is known as a hash value, hash code, digest, checksum, or simply hash. Computer systems use hashing in two major areas:
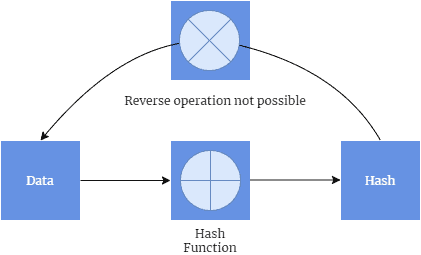
A hash function is an underlying algorithm that computes the hash value of the supplied data. One of the interesting features of a hash function is that it is a one-way algorithm. We can compute the hash value from the give data, but the reverse operation is not possible. Thus, it is not possible to take a hash value and reconstruct the message from it:
Before exploring the available hash functions, let’s explore the characteristics of a good hash function:
There are several such algorithms available to compute the hash value such as the division method, identity hash function, multiplication method.
Let’s explore two popular hashing algorithms: Division Hashing and Identity Hash Function.
In the Division Hashing algorithm, we map the key into one of the slots of the hash table by taking the remainder of the key divided by table size. In mathematical notations, this is represented as  . The value of m is a primer number so that it can generate unique hash values. The table size is usually chosen as a power of two and provides a distribution from
. The value of m is a primer number so that it can generate unique hash values. The table size is usually chosen as a power of two and provides a distribution from  to
to  .
.
Although this is a simple algorithm, it has two major drawbacks.
In the identity hash function, the data itself is the hash value. This algorithm is suitable for small datasets. The meaning of small in this context depends on the size of the data that needs to be used as the hashed value. For example, In Java, a hashcode is a 32-bit integer. Thus, 32-bit Integer and 32-bit Float objects can use the value directly. However, 64-bit Long and 64-bit Double objects can’t use this algorithm.
There are two benefits of this algorithm:
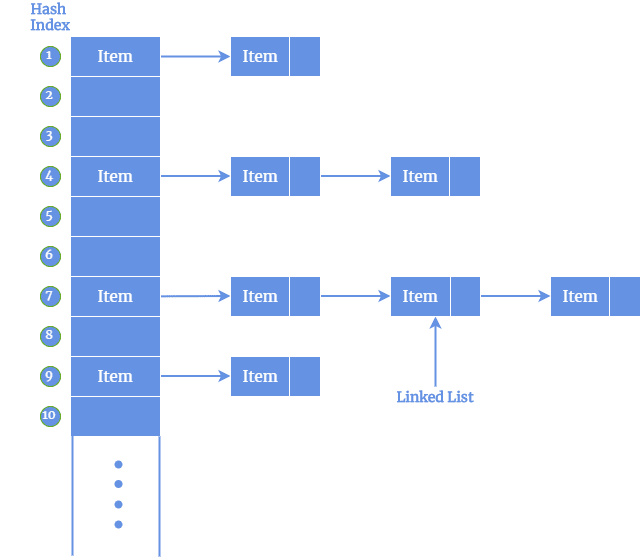
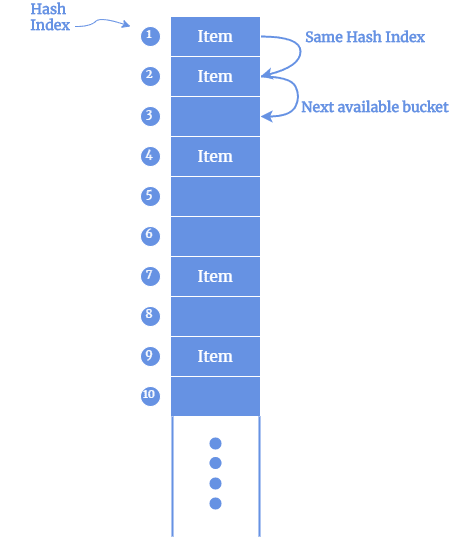
While computing hash value using hash functions, we also need to deal with collisions. A collision occurs when the hash function returns the same hash value for two distinct input data. A good hash function ensures there are fewer collisions. There are several techniques to address collisions.
Data encryption is the process that translates the data from its original form to another form. The original form of data is known as plaintext and the encrypted form of data is known as ciphertext. The ciphertext is decrypted by a secret key.
The main purpose of encrypting data is to protect data confidentiality while it is stored on computer systems or transmitted to other computers over the network. Modern data encryption algorithms ensure data confidentiality and provide key security features including authentication, integrity, and non-repudiation.
The authentication feature allows the verification of a message’s origin. The integrity feature ensures that a message’s contents have not changed since it was sent. Additionally, non-repudiation guarantees that a message sender cannot deny sending the message.
In the data encryption process, relevant data is encrypted with an encryption algorithm and an encryption key. This process results in the ciphertext and can only be viewed in its original form if it is decrypted with the correct key. Based on the key type, there are two main types of encryptions – symmetric encryption and asymmetric encryption.
Symmetric-key encryption uses the same secret key for encrypting and decrypting the data. The major benefit of this type is that it is much faster than the asymmetric encryption type. However, the demerit is that the sender needs to exchange the encryption key with the recipient so that receiver can decrypt it.
To overcome the additional overhead of securely exchange the secret key, organizations have adapted to use an asymmetric algorithm to exchange the secret key after using a symmetric algorithm to encrypt data.
This encryption type is also referred to as public-key cryptography. This is because two different keys one public and one private key are used in this encryption process. The public key, as it is named, may be shared with everyone, but the private key must be protected:
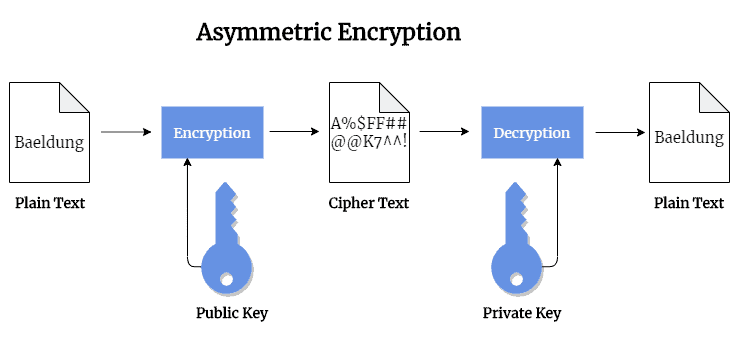
The Rivest-Sharmir-Adleman (RSA) algorithm is a popular public-key encryption that is extensively used to secure sensitive data. The RSA algorithm’s popularity is due to the fact that both the public and private keys can encrypt a message to assure the confidentiality, integrity, authenticity, and non-repudiability of transmitted data.
Although the encryption algorithms offer to protect the data, it is still often the victim of several attacks. These attacks compromise the underlying promises of encryption. The major type of attack on encryption today is the brute force or trying random keys until the right one is found.
Another mode of popular attack is side-channel. This attack types target the cipher implementation, rather than the actual cipher itself. These attacks tend to succeed if there is an error in system design or execution.
In this article, we discussed two major features of data security in computer systems – hashing and encryption.
In the beginning, we talked about hashing that computes a unique hash value of the supplied data.
Later, we discussed encryption that converts the data to a ciphertext and can be restored using a secret key.