Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: June 8, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the problem of finding the number of occurrences of a subsequence in a string. First, we’ll define the problem. Then we’ll give an example to explain it. Finally, we’ll present three different approaches to solve this problem.
We have a string  and a string
and a string  . We want to count the number of times that string occurs in string as a subsequence.
. We want to count the number of times that string occurs in string as a subsequence.
A subsequence of a string is a sequence that can be derived from the given string by deleting zero or more elements without changing the order of the remaining elements.
Let’s take a look at the following example for a better understanding.
Given a string  and a string
and a string  :
:
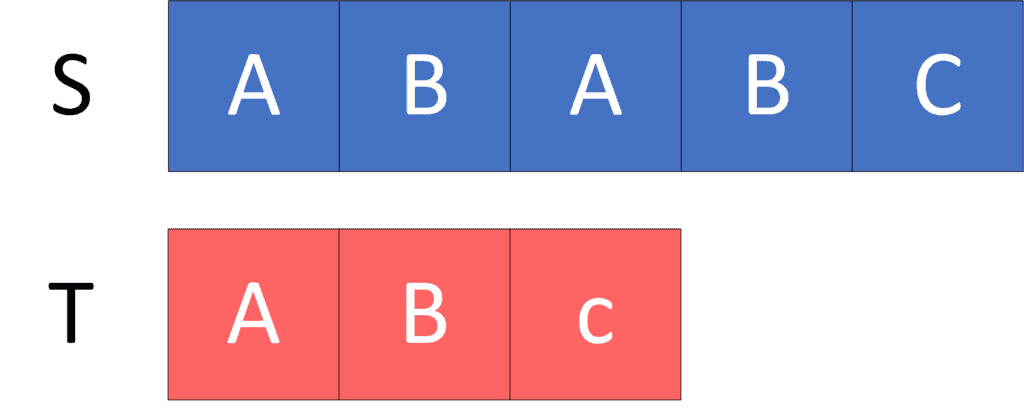
Let’s count the number of occurrences of string in string as a subsequence:
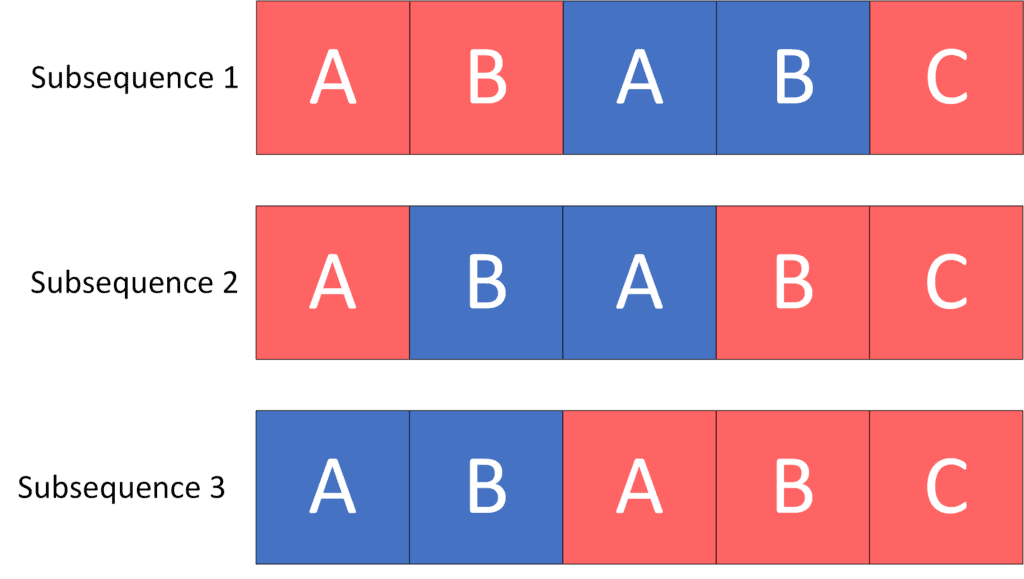
As we can see, there are three subsequences of string that are equal to the string . Thus, the answer to the given example is  .
.
The main idea in this approach is to try every possible subsequence of the string  and see if it matches the string
and see if it matches the string  .
.
For each character of the string , we’ll have two options. We can leave it so that we don’t consider it in the current subsequence, and we move to the next character. Otherwise, we can take it as a character in our subsequence if it’s equal to the current character of the string .
When we reach the end of the string , we get a subsequence of the string that’s equal to the string . As a result, we increase the count of the subsequences by one. Otherwise, we ignore the current subsequence.
Let’s take a look at the implementation of the algorithm:
algorithm RecursionApproach(i, j):
// INPUT
// T = a string
// S = a string in which we count the occurences of T
// i = current position in the string S
// j = current position in the string T
// OUTPUT
// The number of occurenses of T in S
if i = length(S) and j = length(T):
return 1
if i = length(S):
return 0
count <- 0
if j < length(T) and S[i] = T[j]:
count <- count + RecursionApproach(i + 1, j + 1)
count <- count + RecursionApproach(i + 1, j)
return countInitially, we declare the  function that will return the number of subsequences of the string that match the string . The function will have two parameters,
function that will return the number of subsequences of the string that match the string . The function will have two parameters,  and
and  , which will represent our current position in the string and , respectively.
, which will represent our current position in the string and , respectively.
First, since we’re dealing with a recursive function, we’ll set the base conditions to stop searching for answers. We have two situations we have to handle:
and , that means we got a subsequence of that matches the string , so we return  to increase the number of subsequences., that means we didn’t reach the end of . Therefore, we didn’t find a subsequence that matches , and we return
to increase the number of subsequences., that means we didn’t reach the end of . Therefore, we didn’t find a subsequence that matches , and we return  .
.Second, we have to set the recursive calls. For each character of , we have two options; we can either pick the current character, or leave it:
matches the current character of , we try to take it and move both pointers forward., we also have to consider it out of our subsequence. Thus, we try to leave it and move only the pointer of forward.The sum of these two recursive calls will eventually be the answer to the current state.
Finally, the  will return the number of subsequences of the string that match the string .
will return the number of subsequences of the string that match the string .
The time complexity of this algorithm is  , where
, where  is the length of the string , and
is the length of the string , and  is the length of string . The reason for this complexity is that for each character of the string , we have two choices, whether we take it or leave it. However, the picking step is limited to the number of characters inside . So, that gives us a total complexity of
is the length of string . The reason for this complexity is that for each character of the string , we have two choices, whether we take it or leave it. However, the picking step is limited to the number of characters inside . So, that gives us a total complexity of  .
.
The space complexity of this algorithm is  , since the depth of the recursion tree will be at most , as each time we move to the next character in the string .
, since the depth of the recursion tree will be at most , as each time we move to the next character in the string .
The huge complexity of the previous approach comes from calculating each state  multiple times. In this approach, we’ll try to memorize the answer of each state
multiple times. In this approach, we’ll try to memorize the answer of each state  to use it in the future without calculating that state again.
to use it in the future without calculating that state again.
As we see in the previous approach, the answer of state depends on the answers of the state  , and the state
, and the state  . Therefore, we’ll calculate and before calculating the state . Then we’ll calculate the answer of the state depending on the previous answers.
. Therefore, we’ll calculate and before calculating the state . Then we’ll calculate the answer of the state depending on the previous answers.
Finally, the answer to our problem will be stored in the answer of the state  .
.
Let’s take a look at the implementation of the algorithm:
algorithm DynamicProgrammingApproach(S, T):
// INPUT
// S = the string to search within
// T = the string to search for
// OUTPUT
// DP[0,0] = the number of times T occurs in S as a subsequence
DP <- zero-filled array of size (length(S) + 1) times (length(T) + 1)
DP[length(S), length(T)] <- 1
for i <- length(S) - 1 to 0:
for j <- length(T) - 1 to 0:
DP[i, j] <- 0
if S[i] = T[j]:
DP[i, j] <- DP[i, j] + DP[i + 1, j + 1]
DP[i, j] <- DP[i, j] + DP[i + 1, j]
return DP[0, 0]Initially, we declare the  array, which will store the answer of each state . The initial value of the state
array, which will store the answer of each state . The initial value of the state  is equal to , since this was the base case in the previous approach.
is equal to , since this was the base case in the previous approach.
Next, we’ll iterate from the end of the string until the beginning. For each position in the string , we’ll also iterate over the string from the end until the beginning because every state is depending on the states that come after it.
For each state , we’ll check if the current characters of both strings match. If so, we’ll add to the answer of the current state the answer of state , which means we picked the current character of the string . In addition, we add the answer of the state , which means we leave the current character of the string .
Finally, the value of ![DP[0][0]](/wp-content/ql-cache/quicklatex.com-496adc006b1559a4a4185cbf3bf4bb58_l3.svg "Rendered by QuickLaTeX.com") is equal to the number of subsequences of the string that match the string if we start from the beginning of both strings.
is equal to the number of subsequences of the string that match the string if we start from the beginning of both strings.
The complexity of this algorithm is  , where is the length of the string , and is the length of the string . The reason for this complexity is that for each character of the string , we iterate over all the characters of the string , and try to solve each state individually depending on the states that we calculated earlier.
, where is the length of the string , and is the length of the string . The reason for this complexity is that for each character of the string , we iterate over all the characters of the string , and try to solve each state individually depending on the states that we calculated earlier.
The space complexity of this algorithm is , which is the size of the memoization array that we use to store the answer of each state.
In this approach, we’ll optimize the space complexity of the previous one. The main idea here will be the same as the previous approach. The only difference is that since each state depends only on the next state  , where
, where  represents any position of the string , we can reduce the first dimension of the memoization array to
represents any position of the string , we can reduce the first dimension of the memoization array to  instead of
instead of  (the length of the string ).
(the length of the string ).
For each state, we’ll try to store it in an alternating position of the next state. To do that, we’ll get the advantage of the mod operator. So,  will be the current state, and
will be the current state, and  or
or  will be the next state.
will be the next state.
In the end, the answer to our problem will also be stored in the answer of the state .
Let’s take a look at the implementation of the algorithm:
algorithm DynamicProgrammingOptimization(S, T):
// INPUT
// S = the main string
// T = the subsequence string to find in S
// OUTPUT
// the number of times T occurs in S as a subsequence
DP <- zero-filled array of size 2 times (length(T) + 1)
DP[length(S) mod 2, length(T)] <- 1
for i <- length(S) - 1 to 0:
for j <- length(T) - 1 to 0:
DP[i mod 2, j] <- 0
if S[i] = T[j]:
DP[i mod 2, j] <- DP[i mod 2, j] + DP[(1 - i mod 2), j + 1]
DP[i mod 2, j] <- DP[i mod 2, j] + DP[(1 - i mod 2), j]
return DP[0, 0]Initially, we declare the array, which will store the answer of each state . The initial value of the state  is equal to , since it’s the base case here.
is equal to , since it’s the base case here.
Next, we’ll do the same as the previous approach, but instead of putting the original index in the first dimension, we’ll put its module by  .
.
Finally, the value of is equal to the number of subsequences of the string that match the string if we start from the beginning of both strings.
The complexity of this algorithm is , where is the length of the string , and is the length of the string . The reason for this complexity is the same as the previous approach.
The space complexity of this algorithm is  , which is the size of the memoization array that we use to store the answer of each state. The first dimension becomes equal to , since the answer of each position in the string depends only on the answer of the next position,
, which is the size of the memoization array that we use to store the answer of each state. The first dimension becomes equal to , since the answer of each position in the string depends only on the answer of the next position,  .
.
In this article, we presented the problem of finding the number of occurrences of a subsequence in a string.
First, we provided an example to explain the problem. Then we explored three different approaches for solving it.
Finally, we walked through their implementations, with each approach having a better space or time complexity than the previous one.