

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: November 11, 2022
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss the problem of finding a cycle in a singly linked list and the starting point of this cycle.
First, we’ll explain the general idea of the problem and then discuss two approaches to solving it. Secondly, we’ll present two exceptional cases and see how can one of the approaches be updated to handle them.
In the end, we’ll present a comparison between all the provided approaches.
Suppose we have a linked list  , which has
, which has  nodes. We want to check if the list is cyclic or not. Also, we want to find the beginning of this cycle, if found.
nodes. We want to check if the list is cyclic or not. Also, we want to find the beginning of this cycle, if found.
Before we start with the solutions, we need to know what the cycle in a list means.
As we know, the list is a collection of nodes in which each node contains a reference (in other words, a link) to the next node. We say that the list is cyclic when the last node points to one of the nodes in the list
Let’s check the example for better understanding:
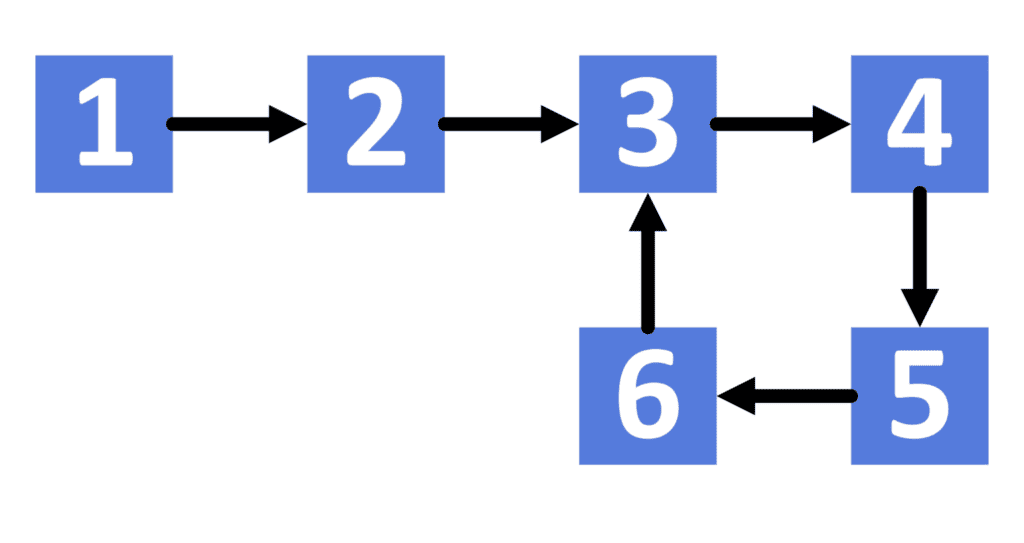
Note that we can have only one cycle inside a list. Besides, the cause of the cycle will always be that the last node is pointing to a node inside the list because each node points to exactly one node.
In the simple list with no cycles, we can iterate over its elements using  loop as follows:
loop as follows:
algorithm iterateList(A):
// INPUT
// A = The linked list
iter <- A.head
while iter != null:
// ...
iter <- iter.nextThe reason is that, since we don’t have a cycle, the last element points to  . Take a look at the example that shows an acyclic list:
. Take a look at the example that shows an acyclic list:
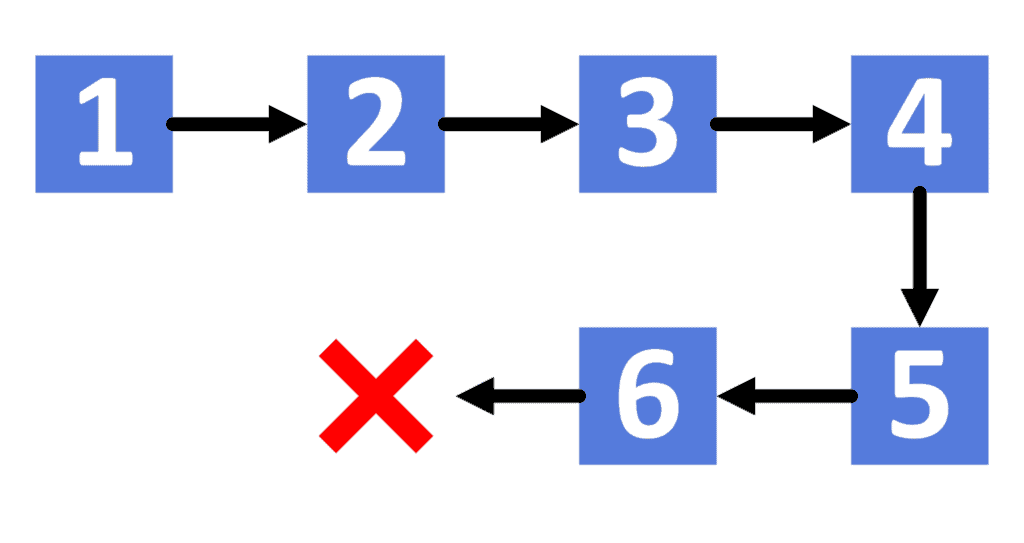
However, when we have a cycle, we can’t iterate using the same way. The reason is that the last node points to another one. Therefore, the algorithm will enter an infinite loop.
To solve this issue, we can add a variable to each node that tells us whether we’ve visited it before or not. Let’s call it  .
.
Take a look at the implementation of the visited approach:
algorithm findCycleVisited(A):
// INPUT
// A = The linked list
// OUTPUT
// Returns the starting node of the cycle if it exists, or null otherwise
answer <- null
node <- A.head
while node != null:
if node.visited = true:
answer <- node
break
node.visited <- true
node <- node.next
node <- A.head
while node != null:
if not node.visited:
break
node.visited <- false
node <- node.next
return answerThe implementation consists of two main steps.
In the first step, we check whether there is a cycle in . At first, we initialize  by . This is so that if we can’t find any loop, the remains .
by . This is so that if we can’t find any loop, the remains .
Next, we iterate over the nodes in using the iterator  . In each step, we check whether we visited the current node before. If so, it means we reached a cycle, and the current node is the starting point. Therefore, we store inside and stop the loop.
. In each step, we check whether we visited the current node before. If so, it means we reached a cycle, and the current node is the starting point. Therefore, we store inside and stop the loop.
In case we haven’t visited this node before, we mark it as visited and continue to the next element.
Once we’re done with the first step, we mark all nodes as unvisited to restore the list to its original state. This is to allow us to use this variable in other algorithms.
Finally, we return the resulting .
The complexity of the visited approach is  , where is the length of the list.
, where is the length of the list.
In some problems or program language, it’s tough to edit the structure of the nodes. As a result, we might not be able to add the  variable. However, we might have a unique variable for each element. Let’s call it
variable. However, we might have a unique variable for each element. Let’s call it  .
.
In case  is an integer in the range
is an integer in the range ![\boldsymbol{[0, MaxVal]}](/wp-content/ql-cache/quicklatex.com-457dd1ae8d0968520e31c9a304552ddb_l3.svg "Rendered by QuickLaTeX.com") , where
, where  is relatively small, we can add a new boolean array with
is relatively small, we can add a new boolean array with  elements. In each step, we check the value of
elements. In each step, we check the value of ![\boldsymbol{visited[node.id]}](/wp-content/ql-cache/quicklatex.com-2bafe47c7704ae17c5c2f0366f38a4be_l3.svg "Rendered by QuickLaTeX.com") , rather than checking the value inside the element.
, rather than checking the value inside the element.
Let’s take a look at the implementation:
algorithm findCycleSmallIntegers(A):
// INPUT
// A = The linked list
// OUTPUT
// Returns the starting node of the cycle if it exists, or null otherwise
answer <- null
node <- A.head
visited <- array of false values
while node != null:
if visited[node.id] = true:
answer <- node
break
visited[node.id] <- true
node <- node.next
return answerFirstly, we initialize with , which will hold the resulting answer. Also, we’ll initialize the array with false values.
Secondly, we’ll iterate over . For each node, we check whether we’ve visited it before or not. To do this, we use the array.
If we haven’t visited it before, we assign  to its location inside and move to the next. Otherwise, we update and break the loop.
to its location inside and move to the next. Otherwise, we update and break the loop.
Finally, we return the resulting .
Note that if we have negative values, such that the id’s range is ![[-a,+b]](/wp-content/ql-cache/quicklatex.com-ea0bd363f4dec584b732b672fcab9594_l3.svg "Rendered by QuickLaTeX.com") , we can still use this approach after shifting all values by
, we can still use this approach after shifting all values by  . Hence, the id’s range will be
. Hence, the id’s range will be ![[0,a+b]](/wp-content/ql-cache/quicklatex.com-845257682182c071d7d891a565365645_l3.svg "Rendered by QuickLaTeX.com") and the position of id
and the position of id  will be
will be  .
.
The complexity of this approach is  , where is the size of the list, and
, where is the size of the list, and  is the maximum value of the ids.
is the maximum value of the ids.
In case the is not an integer or has a relatively large value, we can’t use an array. Thus, we solve this case by using either a TreeSet or a HashSet data structure. In this tutorial, we’ll use a TreeSet to store the visited elements.
Let’s take a look at the implementation:
algorithm findCycleTreeSet(A):
// INPUT
// A = The linked list
// OUTPUT
// Returns the starting node of the cycle if it exists, or null otherwise
answer <- null
node <- A.head
set <- empty TreeSet
while node != null:
if set.contains(node.id):
answer <- node
break
set.add(node.id)
node <- node.next
return answerSimilarly to the previous approach, we initialize with , which will hold the resulting answer. Besides that, we define  as a new empty TreeSet that will hold the visited ids.
as a new empty TreeSet that will hold the visited ids.
Same as before, we’ll use the iterator to iterate over . However, in this approach, we’ll use the  data structure to check whether we reach a visited node.
data structure to check whether we reach a visited node.
If we don’t find the inside the , we move to the next element and add it to . Otherwise, we update the and break the loop.
Finally, we return the .
The complexity of this approach is  , where is the number of elements.
, where is the number of elements.
In this section, we’ll explain a different idea to finding a cycle in a list.
First of all, let’s define two iterators  and
and  initializing them with
initializing them with  .
.
Next, we iterate over  . Each time, we move
. Each time, we move  one step, while we move
one step, while we move  two steps. We continue this process until we either reach
two steps. We continue this process until we either reach  or becomes eqaul to .
or becomes eqaul to .
If we reach , we declare that no cycle is found. On the other hand, if becomes equal to , then we reached a loop and points to one of its nodes.
To find the start of the cycle, we must find the size of the loop first. We can do this by moving only until it becomes equal to again and counting the steps. Hence, we get the size of the cycle denoted as  .
.
Now, let’s start from the beginning of , and from the  node. We keep moving and one step until they meet. At this point we can either return or as the beginning of the cycle.
node. We keep moving and one step until they meet. At this point we can either return or as the beginning of the cycle.
Let’s check the implementation:
algorithm findCycleTwoPointers(A):
// INPUT
// A = The linked list
// OUTPUT
// Returns the starting node of the cycle if it exists, or null otherwise
answer <- null
node1 <- A.head
node2 <- A.head
foundLoop <- false
while node1 != null and node2 != null and node2.next != null:
if node1 = node2:
foundLoop <- true
break
node1 <- node1.next
node2 <- node2.next.next
if not foundLoop:
return null
m <- 1
node1 <- node1.next
while node1 != node2:
node1 <- node1.next
m <- m + 1
node1 <- A.head
node2 <- A.head
for j <- 1 to m:
node2 <- node2.next
while node1 != node2:
node1 <- node1.next
node2 <- node2.next
return node1We can split this implementation into four parts:
one step, and two steps each time. The process continues until they meet. When they meet, we declare finding a cycle. After the loop ends, we check whether we found a loop. If so, we return and terminate the algorithm.. We move until it meets with again. Note that we move the one time before the loop because, at first, they are equal. to and move until it points to the  node. and together until they meet. Once they meet, return any of them.
node. and together until they meet. Once they meet, return any of them.The complexity of this approach is , where is the size of the list. Let’s explain the reason behind the linear complexity.
First of all, let’s explain the idea behind the two iterators. Since is moving twice as fast as , then once will be the first one to enter the cycle. After this, will enter the cycle.
At this point, we can be sure that will catch up to , after at most  steps, because it’s moving faster. Before this happens, we have multiple cases:
steps, because it’s moving faster. Before this happens, we have multiple cases:
came back to meet . is one step before , then in the next step they will meet. Hence, we have a cycle. is two steps before , then in the next step, will be one step before , which is similar to case 2.In general, since moves two steps forward, the distance between both iterators will reduce by one step each time until they finally meet.
As a result, we can conclude that if we have a cycle, then will catch up to , and they’ll meet at the same location after no more than steps.
To get the beginning of the cycle, we started from the beginning of and from the node. Let’s prove that they must meet after no more than steps.
First of all, let’s define the distance as the number of steps needed for to reach . In the beginning, the distance equals , which is the size of the cycle.
Since both iterators move at the same speed, this distance will remain the same. Also, will be the first to enter the cycle, followed by after steps. When this happens, suppose still needs steps to reach .
However, since both of them are inside the cycle, if moves steps forward, it’ll reach its current location. The reason is that the cycle has elements. So, moving steps from a node will get us back to the same node.
As a result, the only way that is still in front of by steps is if they’re at the same node. Hence, this node is the starting node. Also, needs at most steps to reach the beginning of the cycle.
Take a look at the differences between previous approaches:
| Visited Approach | Small Integer Ids Approach | TreeSet Approach | Two-Pointers Approach | |
|---|---|---|---|---|
| Time Complexity |  |
 |
 |
|
| Memory Complexity | |
|
|
 |
| Use Cases | Only when we can edit the structure of nodes | Only when the ids are relatively small integers | General approach | General approach |
By memory complexity, we mean the additional needed memory regardless of the memory already occupied by the list.
As we can see, the visited approach is simpler to implement and easier to understand. But, to use it, we need to add the variable to the nodes of the linked list. Hence, the memory complexity.
On the other hand, when we have small integer ids inside the list, it’s better to use the small integers approach.
Regarding the TreeSet approach, its complexity is bigger than other approaches. Thus, it’s usually not the best one to go with.
A two-pointers approach is a general approach that can handle any case. Therefore, we can always use it.
Nevertheless, it takes a little more time than the visited approach because we iterate over each element about six times.
In this tutorial, we discussed finding a cycle in a singly linked list and the starting point of this cycle.
Firstly, we explained the general idea of the problem and discussed two approaches that solve it. Besides that, we presented two special cases related to the first one.
In the end, we showed a comparison between all the approaches in terms of time and memory complexity. Also, we discussed the best practices for using each of them.