Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 28, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll look at the ensemble learning method in machine learning.
Then, we’ll go over the common types of ensemble learning. Finally, we’ll walk through different ensemble learning applications.
We create machine learning models to generate the best possible predictions for a particular situation. However, a single model may not make the best predictions and may be subject to errors such as variance and bias.
So, we may combine multiple models into a single model. Consequently, This is what is known as ensemble learning to decrease these errors and enhance the predictions.
Then, we will explore ensemble learning techniques that can be used to improve the machine learning process.
In this part, we’ll present the advanced ensemble learning techniques.
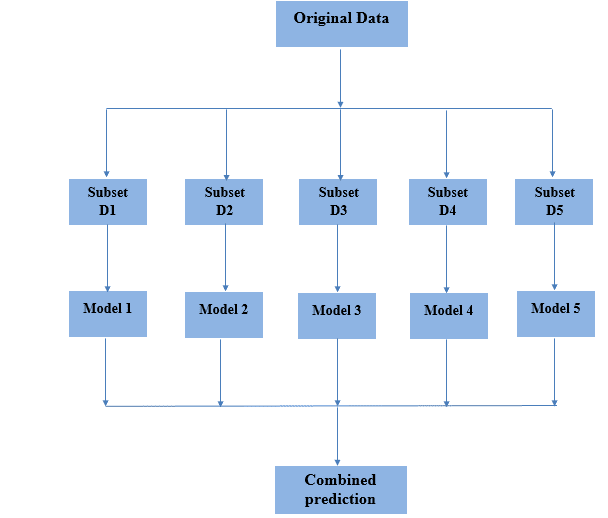
Bagging is a combination of the words bootstrapping and aggregation. It merges the two into a single model. Also, Bagging is a technique that combines multiple models to get a more generalized result.
However, there’s a problem when it comes to training the models. When all models are trained on the same data and then combined, the results are likely to be fairly similar.
Bootstrapping is a sampling strategy that can tackle such a problem. It can be used to create subsets of the original dataset’s observations. The sample is carried out using a replacement method.
When we randomly selected an example from a population and then returned it to the population, this is known as sampling with replacement. The size of the subsets is the same as the original dataset. Also, we use Bags as a term to describe these subsets.
Here are the steps to the bagging process:
The image below will aid in the understanding of the bagging process:
Boosting involves using a collection of algorithms to convert weak learners into strong learners. A poor learner labels instances just slightly better than random guessing. A basic decision tree is an example. In addition, Weighted data is used on these weak learners. For misclassified data, the weighting is unique.
Boosting is done consecutively with each subsequent model to minimize the error of the model preceding it.
Let’s walk through the boosting procedure:
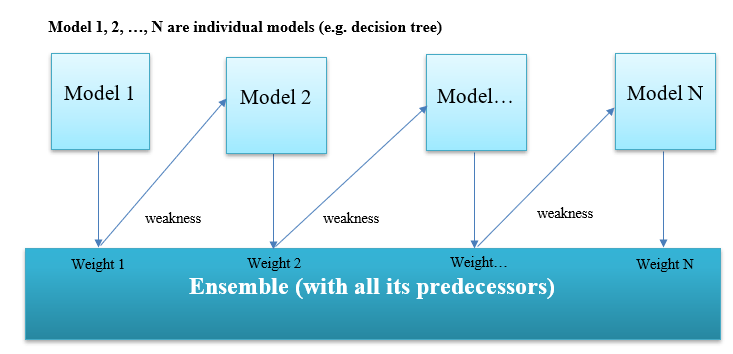
Boosting algorithms aim to enhance prediction accuracy by training a series of weak models, each one correcting for the shortcomings of the one before it (i.e., adjusting the weight).
In general, it combines the outputs of weak learners to generate a strong learner, which increases the model’s prediction power.
Boosting places a greater emphasis on cases that have been misclassified or have more mistakes as a result of previous weak rules.
Stacking is a strategy for training a meta-classifier that leverages the predictions of many classifiers as new features. Many of the classifiers are classified as level one classifiers. We may define a meta-classifier alternatively as a classifier that incorporates the predictions of other classifiers.
To make this process more intuitive, let’s use an image:
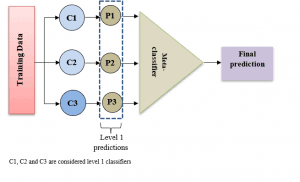
We can see three level-one classifiers in the image above (C1. C2, and C3). We trained the classifiers individually. The classifiers make predictions once they have been taught. So, the meta-classifier is then trained using the predictions that were made. It’s best to have level one predictions from a portion of the training set that wasn’t utilized for training the level one classifier when stacking classifiers.
The goal is to keep information from what we’re trying to predict (target) from getting into the training set. To do this, we divided the training set into two halves. The level-one classifiers should be trained with the first half of the training set. We utilize the classifiers on the remaining half of the training data to create predictions once they’ve been trained.
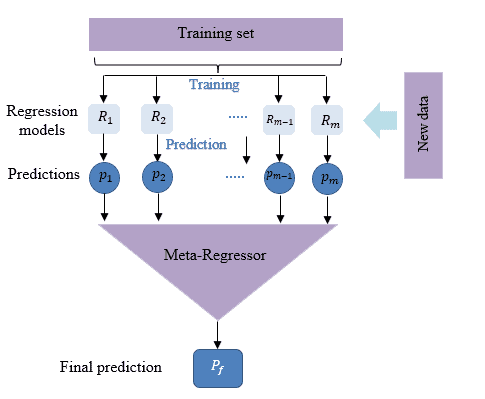
Finally, the predictions trained the meta-classifier. It’s worth mentioning that regression models can also benefit from stacking. Stacking, like classification models, combines the predictions of many regression models using a meta-regressor.
The diagram below describes the technique better :
The number of applications for big ensemble learning has increased in recent years as computer power has expanded, allowing large ensemble learning to be trained in a reasonable amount of time.
In fact, ensemble classifiers have a variety of uses, including:
Any machine learning task seeks to identify a single model that best predicts our desired outcome. Rather than creating a single model and hoping it is the best/most accurate predictor possible, ensemble methods use a variety of models and average them to get a single final model.
In this article, we’ve discussed the fundamentals of ensemble learnings. Also, we discussed different techniques of ensemble learning that allow improving the final classification results.
Then, we presented its importance in various fields.