

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll talk about constituency and dependency parsing.
In order to analyze their differences, we’ll first see how they work with a simple example. Then, we’ll talk about the challenges of parsing as well as some possible use cases.
In computational linguistics, the term parsing refers to the task of creating a parse tree from a given sentence.
A parse tree is a tree that highlights the syntactical structure of a sentence according to a formal grammar, for example by exposing the relationships between words or sub-phrases. Depending on which type of grammar we use, the resulting tree will have different features.
Constituency and dependency parsing are two methods that use different types of grammars. Since they are based on totally different assumptions, the resulting trees will be very different. Although, in both cases, the end goal is to extract syntactic information.
To begin, let’s start by analyzing the constituency parse tree.
The constituency parse tree is based on the formalism of context-free grammars. In this type of tree, the sentence is divided into constituents, that is, sub-phrases that belong to a specific category in the grammar.
In English, for example, the phrases “a dog”, “a computer on the table” and “the nice sunset” are all noun phrases, while “eat a pizza” and “go to the beach” are verb phrases.
The grammar provides a specification of how to build valid sentences, using a set of rules. As an example, the rule  means that we can form a verb phrase (VP) using a verb (V) and then a noun phrase (NP).
means that we can form a verb phrase (VP) using a verb (V) and then a noun phrase (NP).
While we can use these rules to generate valid sentences, we can also apply them the other way around, in order to extract the syntactical structure of a given sentence according to the grammar.
Let’s dive straight into an example of a constituency parse tree for the simple sentence, “I saw a fox”:
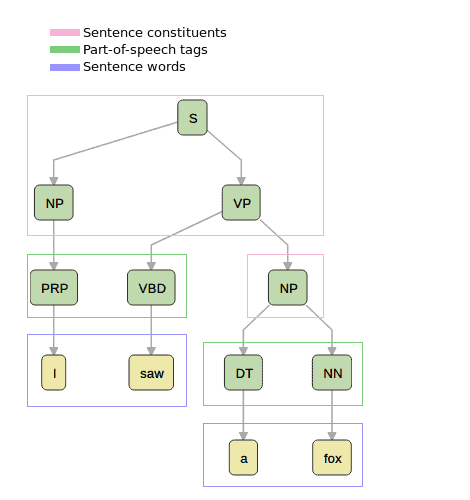
A constituency parse tree always contains the words of the sentence as its terminal nodes. Usually, each word has a parent node containing its part-of-speech tag (noun, adjective, verb, etc…), although this may be omitted in other graphical representations.
All the other non-terminal nodes represent the constituents of the sentence and are usually one of verb phrase, noun phrase, or prepositional phrase (PP).
In this example, at the first level below the root, our sentence has been split into a noun phrase, made up of the single word “I”, and a verb phrase, “saw a fox”. This means that the grammar contains a rule like  , meaning that a sentence can be created with the concatenation of a noun phrase and a verb phrase.
, meaning that a sentence can be created with the concatenation of a noun phrase and a verb phrase.
Similarly, the verb phrase is divided into a verb and another noun phrase. As we can imagine, this also maps to another rule in the grammar.
To sum things up, constituency parsing creates trees containing a syntactical representation of a sentence, according to a context-free grammar. This representation is highly hierarchical and divides the sentences into its single phrasal constituents.
As opposed to constituency parsing, dependency parsing doesn’t make use of phrasal constituents or sub-phrases. Instead, the syntax of the sentence is expressed in terms of dependencies between words — that is, directed, typed edges between words in a graph.
More formally, a dependency parse tree is a graph  where the set of vertices
where the set of vertices  contains the words in the sentence, and each edge in
contains the words in the sentence, and each edge in  connects two words. The graph must satisfy three conditions:
connects two words. The graph must satisfy three conditions:
 in , there must be a path from the root
in , there must be a path from the root  to .
to .Additionally, each edge in has a type, which defines the grammatical relation that occurs between the two words.
Let’s see what the previous example looks like if we perform dependency parsing: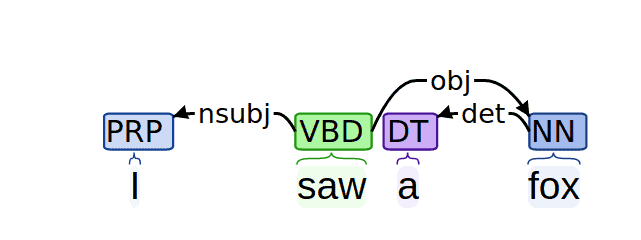
As we can see, the result is completely different. With this approach, the root of the tree is the verb of the sentence, and edges between words describe their relationships.
For example, the word “saw” has an outgoing edge of type nsubj to the word “I”, meaning that “I” is the nominal subject of the verb “saw”. In this case, we say that “I” depends on “saw”.
Parsing natural language presents several challenges that don’t occur when parsing, for example, programming languages. The reason for this is that natural language is often ambiguous, meaning there can be multiple valid parse trees for the same sentence.
Let’s consider for a moment the sentence, “I shot an elephant in my pajamas”. It has two possible interpretations: one where the man is wearing his pajamas while shooting the elephant, and the other where the elephant is inside the man’s pajamas.
These are both valid from a syntactical perspective, but humans are able to solve these ambiguities very quickly – and often unconsciously – since many of the possible interpretations are unreasonable for their semantics or for the context in which the sentence occurs. However, it’s not as easy for a parsing algorithm to select the most likely parse tree with great accuracy.
To do this, most modern parsers use supervised machine learning models that are trained on manually annotated data. Since the data is annotated with the correct parse trees, the model will learn a bias towards more likely interpretations.
So how do we decide what to use, between constituency and dependency parsing? The answer to this question is highly situational, and it depends on how we intend to use the parsing information.
Dependency parsing can be more useful for several downstream tasks like Information Extraction or Question Answering.
For example, it makes it easy to extract subject-verb-object triples that are often indicative of semantic relations between predicates. Although we could also extract this information from a constituency parse tree, it would require additional processing, while it’s immediately available in a dependency parse tree.
Another situation where using a dependency parser might prove advantageous is when working with free word order languages. As their name implies, these languages don’t impose a specific order to the words in a sentence. Due to the nature of the underlying grammars, dependency parsing performs better than constituency in this kind of scenario.
On the other hand, when we want to extract sub-phrases from the sentence, a constituency parser might be better.
We can use both types of parse trees to extract features for a supervised machine learning model. The syntactical information they provide can be very useful for tasks like Semantic Role Labeling, Question Answering, and others. In general, we should analyze our situation and assess which type of parsing will best suit our needs.
In this article, we’ve seen how dependency and constituency parsing work. We’ve examined their differences with the help of a simple example, and we’ve seen when it’s best to use one or the other.