

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll explore the concepts of the consistency model in computer science. This will help us understand why it’s important for concurrent and distributed systems. This is the foundation on which different systems dealing with data offer guarantees related to their data.
2. Why Do We Need a Consistency Model?
So, what is a consistency model? A consistency model establishes a contract between a process and a system. Under this contract, the system guarantees that if a process follows the rules of memory operation, the result of such operation will be predictable.
We need this guarantee as we often deal with data shared across competing processes and threads. They must perform different operations on the same data simultaneously and still need the data to change only in the allowed ways; in other words, they remain consistent.
Moreover, this is further complicated when we distribute that data across multiple nodes that are logically or physically separated. Hence, concurrent access to data managed by a distributed system requires explicit guarantees in terms of data consistency that we can expect:
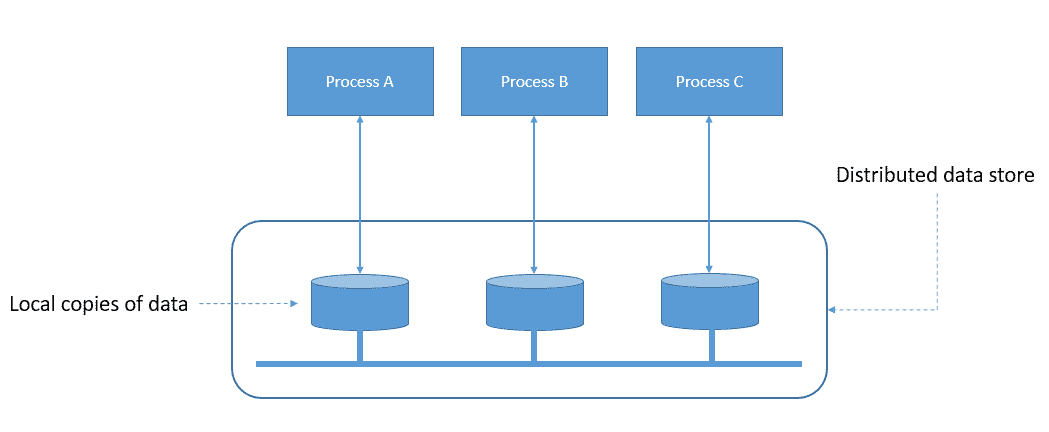
For instance, in the example above, multiple processes operate on their local copy of data. However, the local copies are part of a distributed data store. Now, when a process changes its local copy, can other processes expect to see this change in their local copies?
This expectation is shared by the application processes and the memory implementation of the distributed data store system. To address this, the data store needs to implement a consistency model and impose certain usage rules for the processes operating on the data.
Although the discussion regarding consistency models centers around distributed systems, it’s equally important for a single-node concurrent system. Most of the fundamental concepts were formulated for single-node concurrent systems.
3. Some Fundamental Concepts
By now, we’ve seen some terms that need to be defined properly as we discuss consistency models. First, we talked about processes performing operations. Here, a process is an instance of a computer program that may comprise one or more threads of execution.
Now, systems have a logical state which changes over time. Thus, an operation represents a transition from state to state. We can also give every transition a unique name. For instance, a counter may have operations like increment, decrement, and read.
In general, operations take some finite time to finish. To model this better, an operation is said to have an invocation time and a strictly greater completion time if the operation completes. These are given by an imaginary, perfectly synchronized, and globally accessible clock:
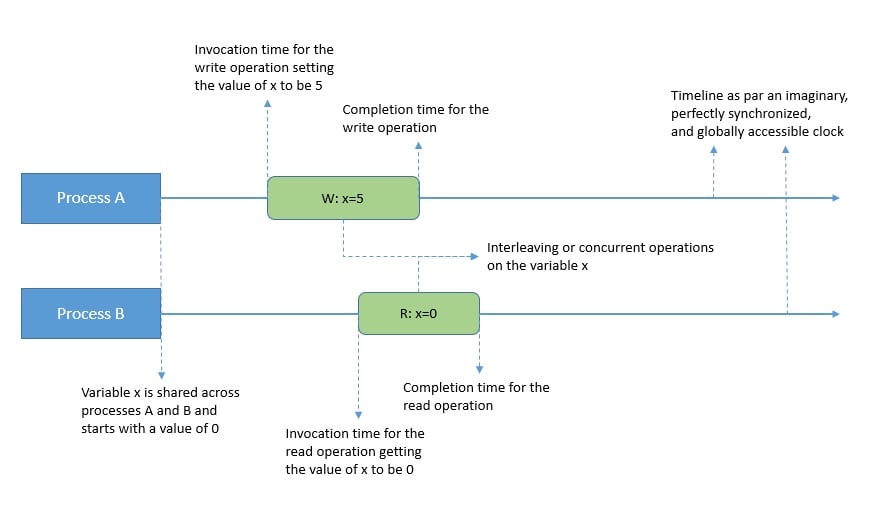
As operations take time, multiple operations being executed by different processes may overlap. This gives rise to concurrent operations. For instance, two operations are said to be concurrent if there’s some time during which they both execute.
The collection of operations, including their concurrent structure, is called a history. A consistency model is thus a set of histories. These models are used to define which histories are legal in a system. They do so by defining rules for history’s apparent order and visibility.
Generally, we refer to a smaller, more restrictive consistency model as “stronger”, and a larger, more permissive consistency model as “weaker”. Now, how strong consistency model a system supports has a bearing on many system attributes, like availability and performance.
4. Categorization of Consistency Models
Consistency models have been an active area of research for many decades now. So, not surprisingly, the vocabulary of consistency is often overlapping and confusing. However, Atul Adya’s PhD thesis submitted in 1999 tries to create a reasonable combined taxonomy of consistency semantics.
Moreover, consistency and isolation are often used interchangeably in the academic literature. However, isolation is often described in a transaction with one or more read-and-write operations. On the contrary, consistency has more to do with atomic read and write operations.
Different consistency models try to address different application concerns that often conflict with each other. For instance, an application’s resilience to read stale data values vs. its ability to support higher throughput for data processing.
As we’ll see later while discussing individual consistency models, they’re often hierarchical. Here, a stronger consistency model imposes more restrictions while respecting those imposed by a weaker consistency model. The relationship between these models tends to form a graph:
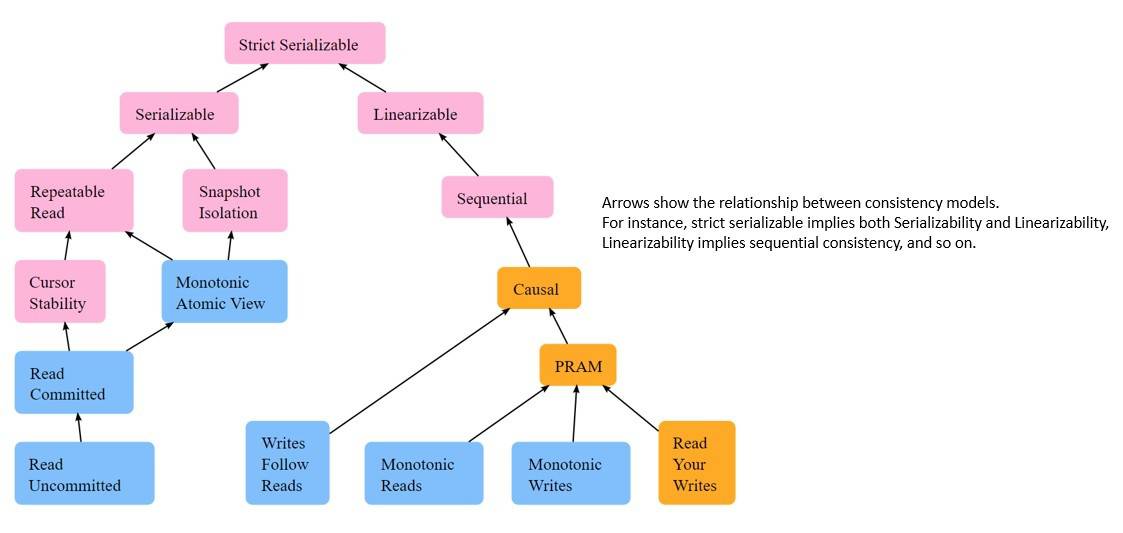
Jepsen, an organization dedicated to distributed systems safety research, has compiled the above map of consistency models. The color of each model shows how available each model is, for a distributed system on an asynchronous network. But, we’ll not go into that detail in this tutorial.
This map isn’t exhaustive of all consistency models. For instance, most distributed systems these days support a fairly weak consistency model called eventual consistency. However, in this tutorial, we’ll only cover some of the basic consistency models and establish the relation between them.
5. Stronger Consistency Models
Two types of methods define and categorize consistency models, issue, and view methods. The issue method describes the restrictions that define how a process can issue operations. The view method defines the order of operations visible to the processes. Now, different consistency models enforce different conditions.
In this section, we’ll examine some of the stronger consistent models.
5.1. Linearizability
Linearizability is a single-object and single-operation consistency model. It requires that every operation appears to take place atomically. Moreover, these operations must appear to follow some order that is consistent with the real-time ordering of these operations.
Here, real-time refers to time in the real world, as indicated by a wall clock. For instance, if an operation completes before another operation begins, then the second operation should logically take effect after the first operation:
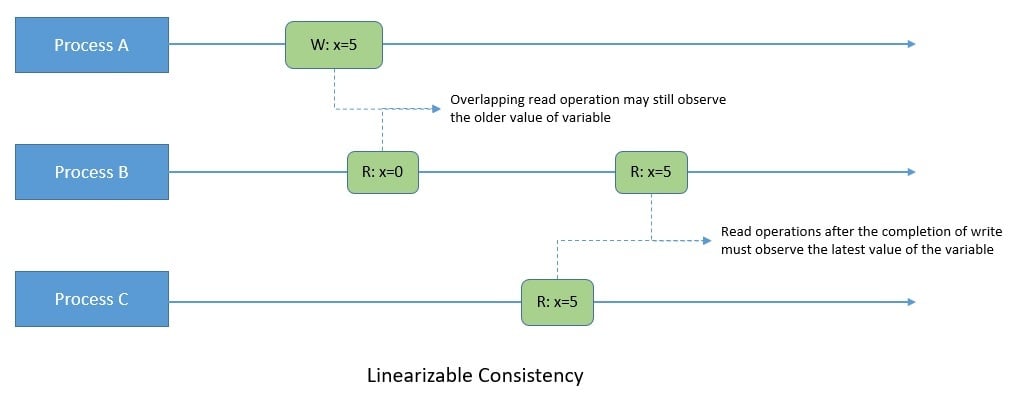
Under linearizability, the write operations should appear to be instantaneous. In other words, once a write operation completes, all later read operations should return the value of that write or the value of a later write. Here, “later” is defined by the wall clock’s start time.
Interestingly, if operations on each object in a system are linearizable, then all operations in the system are linearizable. Linearizability was introduced by Herlihy and Wing in their 1990 paper Linearizability: A Correctness Condition for Concurrent Objects.
5.2. Serializability
Serializability is a multi-object and multi-operation model. It’s a transactional model, where transaction refers to a group of one or more operations over one or more objects. Here, transactions occur atomically and appear to have occurred in some total order.
A key aspect of serializability is that it has no real-time constraints. For instance, if process A completes a write operation and subsequently process B begins a read operation, process B is not guaranteed to observe the effect of the earlier write operation:
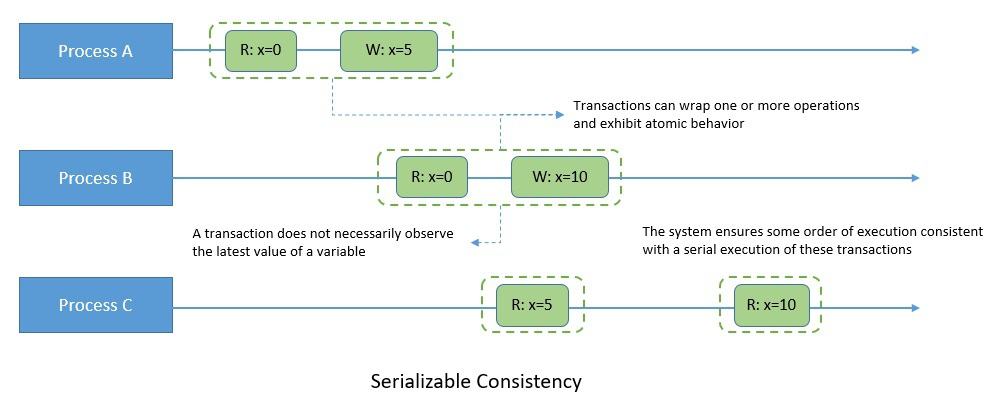
Moreover, serializability also does not impose any requirement for per-process order between transactions. Hence, a process can observe a write and then fail to observe the same write in a subsequent transaction, even if the same process did the write.
However, it does impose a strict restriction on the total order of transactions. Formally speaking, a serializable execution is an execution of operations of concurrently executing transactions that produce the same effect as some serial execution of those same transactions.
5.3. Strict Consistency
Strict consistency is the strongest consistency model. Under this model, a write operation by any process needs to be seen instantaneously by all processes. Thus, the operations must appear to occur in some order, consistent with their real-time ordering.
The model implies that if operation A completes before operation B begins, then A must appear to precede B in the serialization order. Thus, we can also think of strict consistency in terms of a serializable system that is compatible with real-time order:
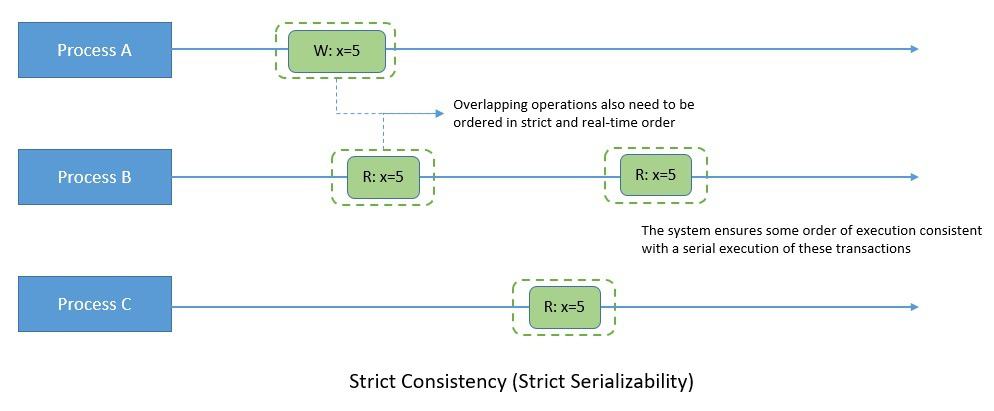
Although strict consistency is deterministic, it’s quite rigid in its constraints. It requires instantaneous exchange of messages, which is not practical, especially for distributed systems. Hence it’s only relevant for thought experiments and formalism.
Strict consistency inherently implies both serializability and linearizability. Hence, we can think of strict consistency as serializability’s total order of transactional multi-object operations plus linearizability’s real-time constraints. This draws from what we discussed in earlier sub-sections.
6. Weaker Consistency Models
Strong consistency models are often quite restrictive for practical applications. Hence, several weaker consistency models have been proposed for better performance and scalability. These are generally achieved by weakening the restrictions of stronger consistency models like serializable and linearizable. Let’s examine some of the weaker consistency models.
6.1. Sequential Consistency
Sequential consistency is a weaker consistency model than linearizability as it drops the real-time constraints. It requires that the operations appear to take place in some total order, consistent with the order of operations on each process.
In a sequentially consistent system, process B may read arbitrarily stale state. However, once process B has observed some operation from process A, it can never observe a state before that operation. Hence, a process in such a system may be far ahead or behind other processes:
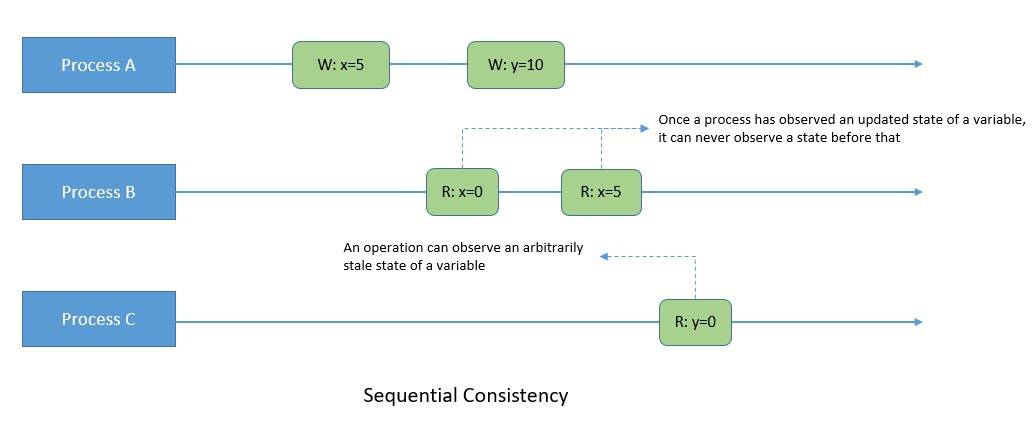
As we can see, sequential consistency does not impose real-time constraints but it does have the property of total ordering. Hence, write operations by different processes have to be seen in the same order by all processes. Leslie Lamport proposed sequential consistency in his 1979 paper.
He defines the model to imply the result of any execution to be the same as if the operations of all the processes were executed in some sequential order. Moreover, the operations of each process appear in this sequence in the order specified by its program.
6.2. Causal Consistency
Causal consistency further reduces the constraints of sequential consistency. It only requires that the causally related operations appear in the same order for all processes. However, processes may observe different orders for causally independent operations.
Hence, only write operations that are causally related need to be seen in the same order by all processes. For instance, two write operations can become causally related if one write to a variable is dependent on a previous write to any variable if the process doing the second write has just read the first write:
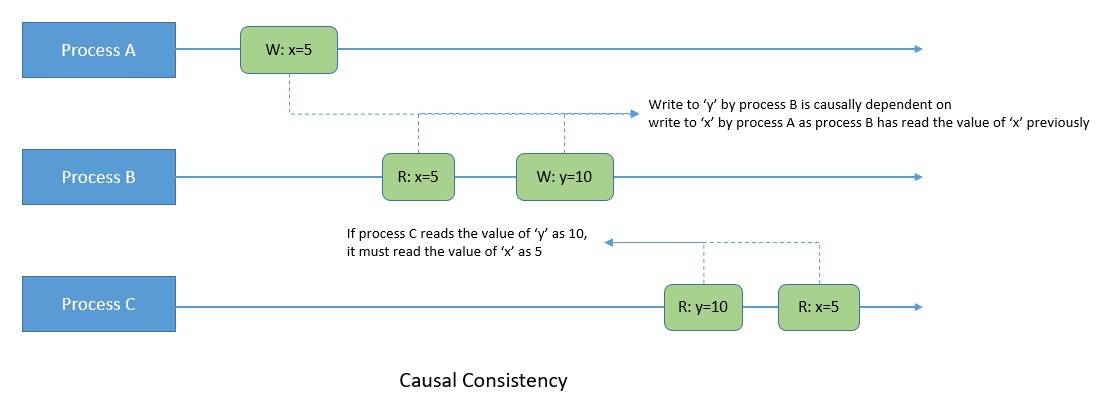
Interestingly, the observed variables’ order is more important than the actual value observed while reading. Hence, if operation ‘b’ takes effect from an earlier operation ‘a’, the causal consistency guarantees that all processes see operation ‘b’ after operation ‘a’.
Here, the causal memory originates from Lamport’s definition of the happens-before relation. It captures the notion of potential causality by relating an operation to previous operations by the same process and operations on other processes whose effects could have been visible.
6.3. Pipeline Random Access Memory (PRAM)
Under the PRAM consistency model, all processes view the operations of a single process in the same order issued by that process. However, operations issued by different processes can be viewed differently from different processes.
For instance, a pair of write operations executed by a single process is observed from all processes in the order the process executed them. But writes from different processes may be observed in different orders from different processes:
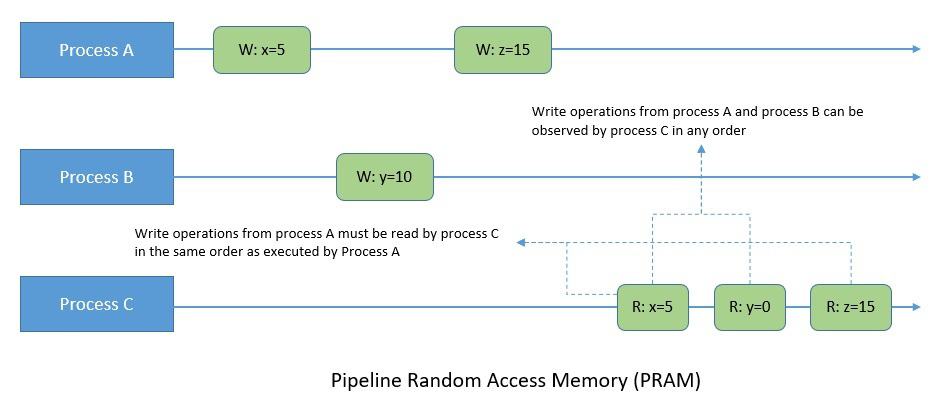
Lipton and Sandberg presented PRAM in their 1988 paper. PRAM is a weaker model than processor consistency as it relaxes the need to maintain coherence to a location across all its processes. Thus, it can achieve better concurrency and, consequently, performance.
Here, “reads” to any variable can be executed before “writes” in a process. However, the “read before write”, “read after read”, and “write before write” order is still preserved. Hence, it’s equivalent to Read Your Writes, Monotonic Writes, and Monotonic Reads consistency models.
6.4. Repeatable Read
Repeatable read is a consistency model that forms part of the requirement for serializability. It’s quite close to serializability, apart from the fact that it allows phantoms. A phantom read occurs when two identical read operations observe two different sets of results.
Here, while transaction T1 reads a set of objects based on a predicate, transaction T2 can modify any of those objects read by transaction T1. However, on repeated reads, transaction T1 would still read the same values, although it can observe phantom values for the original predicate:
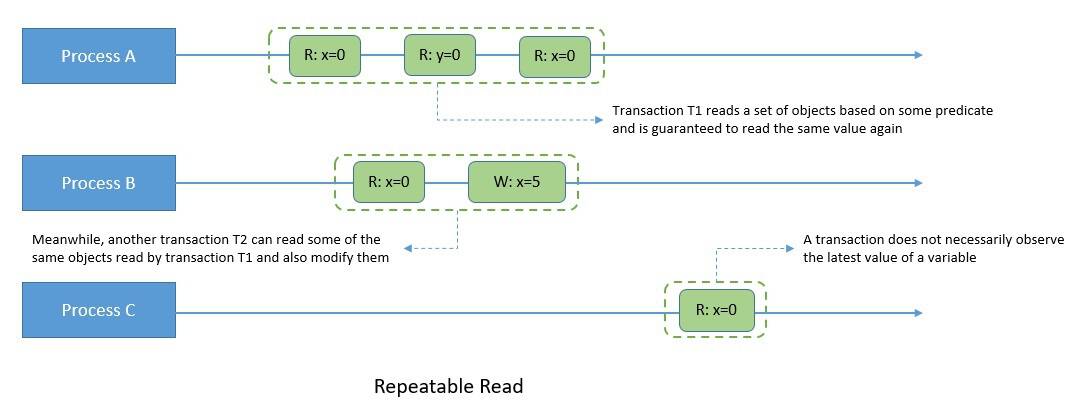
However, repeatable read guarantees to prevent dirty reads and non-repeatable reads. A dirty read happens on data that has been modified by a transaction but has not been committed. A non-repeatable read might occur when read locks aren’t acquired before performing a read operation.
Repeatable read is a stronger consistency model than cursor stability. In cursor stability, transactions read an object using a cursor which ensures that “lost updates” do not occur. Strengthening it further, the repeatable read model ensures stability of every record read, rather than cursors.
6.5. Snapshot Isolation
Snapshot isolation is another transactional model that forms part of the requirements for serializability. Here, each transaction appears to operate on an independent, consistent database snapshot. The changes are only visible within a transaction until it’s committed.
For instance, transaction T1 begins its snapshot and modifies an object. Now, if transaction T2 commits a write to the same object after transaction T1’s snapshot began, but before it could commit. This requires transaction T1 to abort:
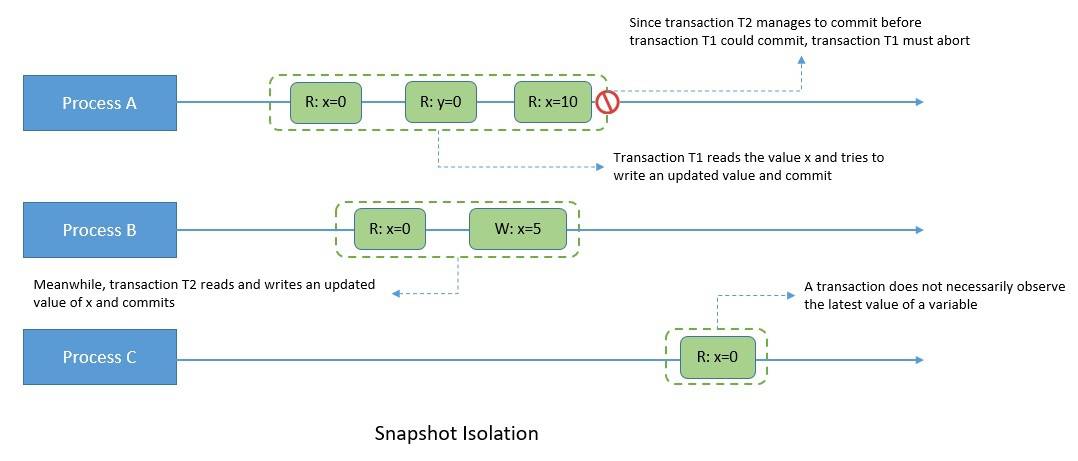
While serializability enforces a total order of transactions, snapshot isolation only forces a partial order. Here, the operations in one transaction may interleave with those from other transactions. Moreover, like repeatable read, snapshot isolation also implies read committed.
Various database management systems, like Oracle, MySQL, PostgreSQL, and Microsoft SQL Server, have widely adopted snapshot isolation levels. This is primarily because it allows better performance than serializability while avoiding most concurrency anomalies.
6.6. Monotonic Atomic View (MAV)
Under MAV, once another transaction observes some of the effects of a transaction, the second transaction observes all the effects of the first transaction. Hence, it expresses the atomic constraint from ACID that all (or none) of a transaction’s effect should occur.
Thus, MAV is a stronger consistency model than read committed. Here, for instance, if transaction T2 observes a write operation from transaction T1, then all other write operations of transaction T1 should also be visible to transaction T2:
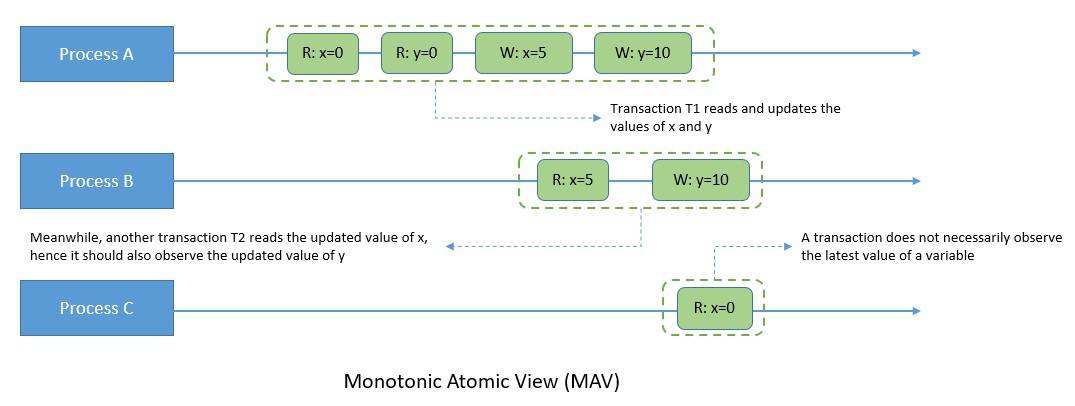
MAV was coined by Bailis, Davidson, and Fekete et. al. in their paper in 2013. While it’s not widely discussed in the literature, it’s particularly helpful in enforcing foreign key constraints and ensuring indices and materialized views reflect their underlying objects.
Both repeatable read and snapshot isolation offer stronger guarantees than MAV. However, a system supporting MAV can be totally available. This means that even in the presence of network partitions, every node in the system can make progress.
7. Consistency Model in Practice
As we’ve seen earlier, consistency models impose more restrictions on the system as we move from weaker to stronger models. Hence, stronger models can avoid more data inconsistency scenarios. However, they can’t scale well and hence offer poor performance.
Most of the traditional relational databases support multiple consistency models with a default choice. However, they may not use a consistent vocabulary. For instance, Oracle Database offers read commits and serializable isolation levels, with read committed being the default.
However, these SQL databases offer expensive vertical scaling and are difficult to scale horizontally. Hence, while offering much stronger data consistency, they fail to handle the growing velocity, volume, and variety of data. This led to the introduction of NoSQL databases. NoSQL databases offer great horizontal scalability while supporting weaker consistency models, like eventual consistency. For instance, Cassandra supports a tunable consistency model from strong to eventual, with eventual being the default.
So, most of the data stores today offer multiple options for consistency models. The choice depends on the requirements of an application. For instance, some applications may not require consistency across multiple records; hence, a weaker model can suffice while offering better performance!
8. Conclusion
In this tutorial, we went through some of the basic concepts related to the study of consistency models in computer science. Here, we also reviewed some of the stronger consistency models and some of the weaker ones.