Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: June 12, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
The ASCII (American Standard Code for Information Interchange) code consists of a 7-bit binary standard used to encode a set of 128 graphic and control symbols.
Specifically, the ASCII table contains 95 graphic symbols. These symbols include the Latin alphabet (lower and upper case), common punctuation marks, common math signs, and Arabic numeric digits.
The ASCII table also embraces 33 control symbols. These symbols are employed to manage the processing and provide metadata of ASCII-encoded information.
In this article, first, we will take a look at the history and documentation of ASCII. Next, we go deep into the ASCII table to learn how each symbol is encoded.
After the theoretical background, we’ll see how to encode particular symbols and words from the graphic form to decimal ASCII code and, finally, to binary code. Similarly, we’ll see how to decode binary/decimal ASCII codes.
Finally, we will briefly review some ASCII variants and where they are employed.
In the beginning, the codes used on telegraphic transmissions inspired the development of the ASCII code. Thus, it was designed to work with a 7-bit based teleprinter. However, the ASCII code’s developers also planned codes suited to devices other than teleprinters.
The American Standard Association (which is today’s American National Standards Institute) proposed ASCII in 1963. After that, the organization reviewed ASCII several times, maintaining it along the way.
The extra non-telegraphy codes included on ASCII and a well-organized and sorted distribution of codes (compared with earlier telegraphy codes) established ASCII as the USA’s standard federal computer communication language in 1968.
With the rising of the Internet, ASCII spread very fast in the following years. The ASCII code became especially popular by encoding characters of emails and HTML pages.
Since 2008, UTF-8 surpassed ASCII as the most common Internet encoding. However, UTF-8 embedded ASCII as its first 128 codes and just extended the table with 128 extra codes.
As we noted above, ASCII consists of a 7-bit code with 128 symbols (95 graphic symbols and 33 control symbols).
Most important, ASCII establishes that particular sequences of bits (the code) represent specific symbols. Therefore, ASCII enables, for example, a digital device to process, store, and present data naturally recognized by humans.
The codes of ASCII are typically exhibited in a table, called the ASCII table, containing the symbols associated with each code, as well as their descriptions and decimal/binary code representations:
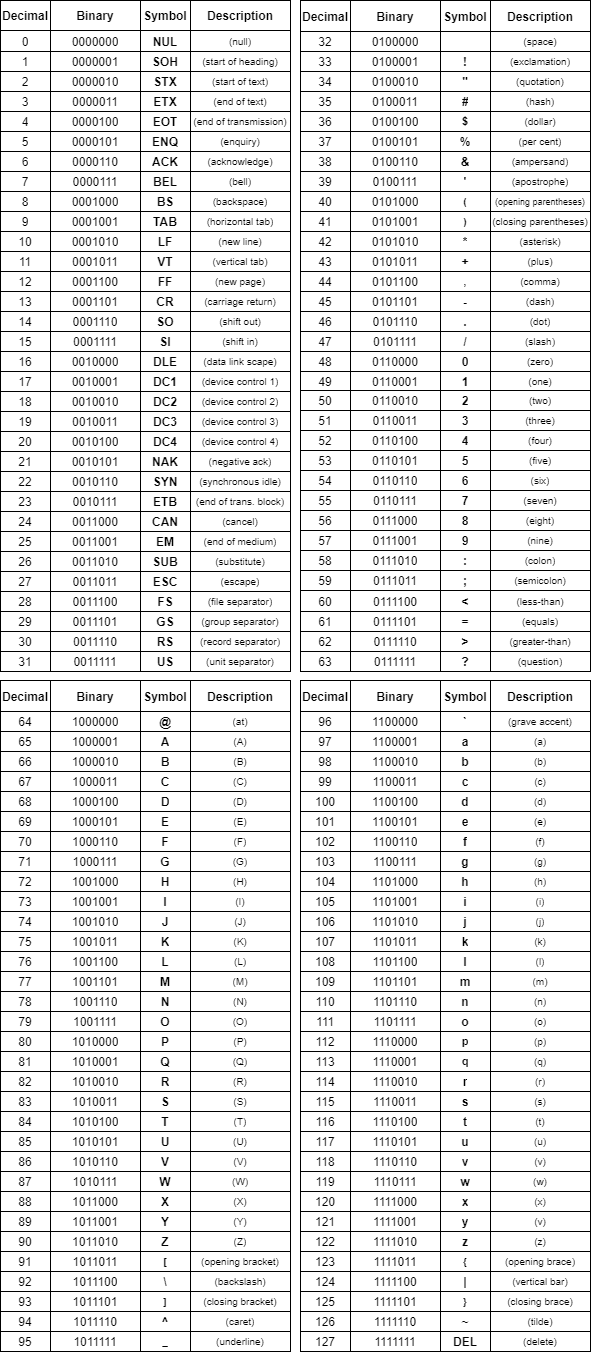
The ASCII table groups most of the control symbols in the code range from 0 to 31. The unique exception is the symbol DEL, which has the code 127. This exception tackles the teletype machines’ process for correcting typing errors.
Note that teletypes punch the punchcard as the operator presses keys. Thus, there is no backspace function available. In this way, the process to correct errors consists of backing the punchcard to the position of the error and replacing its respective code with a code that’s ignored when reading and processing the punchcard.
Teletype machines typically represent the ignoring code by punching all the holes in the error position, generating an ASCII DEL code (127).
The codes of graphic symbols are between 32 and 126 in the ASCII table. ASCII graphic symbols have, among others, Latin letters, Arabic numerals, punctuation marks, and mathematical operators.
In particular, we do not recognize the space (32) as a printable symbol. Thus, space (32) is specially categorized as an invisible graphic symbol.
At last, the ordering of ASCII graphic symbols follows a specific organization known as ASCIIbetical. The ASCIIbetical order allocates the uppercase letters before the lowercase letters (for example, ‘Z’ comes before ‘a’). Also, numbers come before letters, and other symbols receive codes that intercalate sets of letters and numbers.
Encoding a random string to binary ASCII code typically requires an ASCII table with the respective decimal values of each of the string’s characters. After encoded, digital devices can process, store, or transmit these codes. However, displaying ASCII to human operators of such devices involves decoding the codes from binary to a readable version.
In the following subsections, we will learn both the encoding and decoding processes of ASCII.
To demonstrate how to convert a sequence of characters to binary ASCII code, we will employ the string “Baeldung” and execute, step by step, the encoding process on it.
First, we look up the ASCII table to establish the decimal values corresponding to each character of the string:
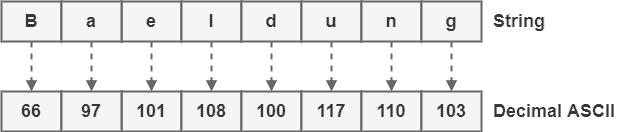
When we work with Latin letters, it’s critical to notice that ASCII is case-sensitive. Thus, in our example, the code of “B” (which is 66) is different from the code of “b” (which is 98).
After defining the decimal ASCII code, we’re able to convert them to binary codes. In order to do that, we transcribe each decimal code to a 7-bit code. Each position  of the binary ASCII code (in other words, each bit) indicates the value of
of the binary ASCII code (in other words, each bit) indicates the value of  . Furthermore, the significance of bits grows from right to left. In this way, the binary ASCII code has the following structure:
. Furthermore, the significance of bits grows from right to left. In this way, the binary ASCII code has the following structure:

With this structure, to get the respective binary code of a decimal ASCII code, we should allocate a bit 1 to the positions P in such a way that the sum of their values results in the decimal ASCII code. Other positions receive a bit 0. Taking into account the encoding process of “Baeldung”, we have the following binary ASCII codes:
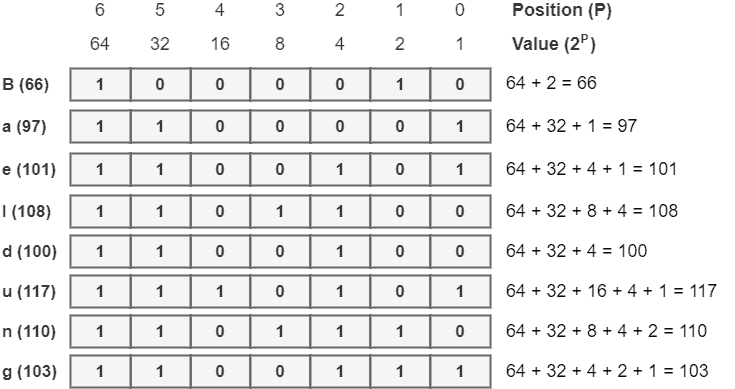
So, the binary ASCII code for the string “Baeldung” is 1000010 1100001 1100101 1101100 1100100 1110101 1101110 1100111.
To demonstrate the decoding process from binary ASCII to a readable string, we’ll use the following code: 1010011 1100011 1101001 1100101 1101110 1100011 1100101.
To execute the decoding process of a binary ASCII code, we will use the same structure of positions/values previously employed for the encoding process. However, now, we must fill the positions with their respective bits of the provided binary code. Then we sum the values of positions with a bit 1 to get decimal codes:
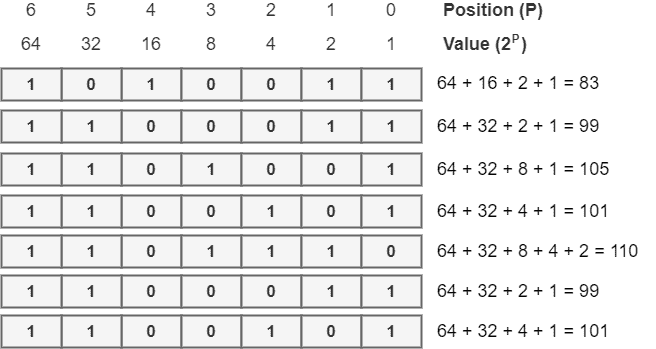
Next, we look up the ASCII table to convert the decimal codes to a readable string:
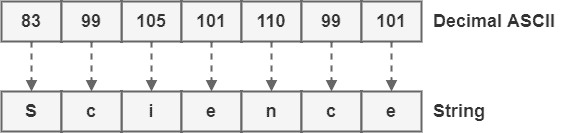
Finally, we conclude that the readable string for the provided ASCII code is “Science”.
According to the popularization of computer technologies, particular standardization bodies adapted the ASCII code to tackle new symbols employed in specific languages. Examples of these symbols are letters with accents and cedilla.
Another phenomenon that encouraged the creation of ASCII variants was the rising of 8-bit (and, later, 16-, 32-, and 64-bit) architectures for computers. The minimal data type recognized by programming languages typically became a byte with 8 bits. Thus, new encodings frequently used the extra bit to enlarge the ASCII table.
New encodings kept ASCII’s original table (0 to 127) and extended it with new symbols. Two 8-bit encodings that are of particular interest are:
In this article, we studied the ASCII code and table. First, we reviewed the history of ASCII. Next, we analyzed the ASCII table and codes and understood how the standard is organized. Then, we learned how to encode/decode a generic string with ASCII. Finally, we took a look at the most common ASCII variants.
We can conclude that ASCII is a crucial standard that inspires and composes the most popular current information encoding standards, such as UTF-8.