

1. Introduction
In this tutorial, we’ll talk about Radix Sort, which is an  sorting algorithm.
sorting algorithm.
2. Sorting in Linear Time
In a sorting problem, we have an array  of
of  objects and an ordering relation
objects and an ordering relation  . Our goal is to sort so that each two consecutive elements
. Our goal is to sort so that each two consecutive elements ![a[j]](/wp-content/ql-cache/quicklatex.com-2afd9b90234378f963da9f507a4435cf_l3.svg "Rendered by QuickLaTeX.com") and
and ![a[j+1]](/wp-content/ql-cache/quicklatex.com-37e20c64b8edd2b514fa89635f0306c3_l3.svg "Rendered by QuickLaTeX.com") are in the correct order:
are in the correct order: ![a[j] \prec a[j+1]](/wp-content/ql-cache/quicklatex.com-dabb03bef5d03f0a4a700f4184f08a73_l3.svg "Rendered by QuickLaTeX.com") .
.
When dealing with numbers, the relation is one of the  . Here, we’ll assume the input array contains integers and should be sorted non-decreasingly, i.e., according to the relation
. Here, we’ll assume the input array contains integers and should be sorted non-decreasingly, i.e., according to the relation  . Also, we’ll use 1-based indexing.
. Also, we’ll use 1-based indexing.
Comparison sort algorithms sort the input by comparing their elements to decide their relative order. Such methods are, e.g., QuickSort and Merge Sort. The lower bound of the worst-case time complexity of all comparison sorts is  .
.
The Radix Sort algorithm, however, has linear time complexity.
3. Radix Sort
This algorithm sorts an array  of integers by sorting them on their digits from the least to the most significant one.
of integers by sorting them on their digits from the least to the most significant one.
First, the algorithm sorts them by their least significant digits using Counting Sort. As a result, the numbers ending in 0 precede those ending in 1 and so on. Then, Radix Sort sorts the thus obtained array on the second-least significant digit, breaking ties by the order from the previous step. So, we must use a stable sort algorithm in each step.
The algorithm goes on like this until it sorts the numbers on the most significant digit. Once it does, the whole input array gets in the desired order.
3.1. Radix Sort in Action
Let’s take a look at an example:
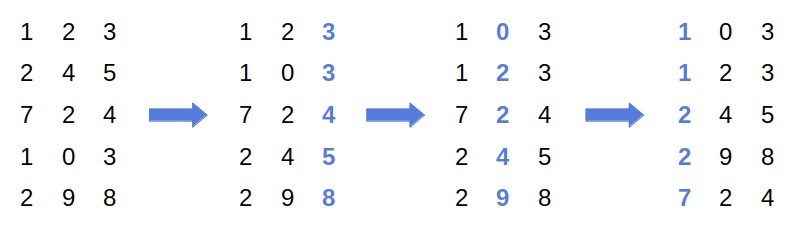
First, we sort the input on the least significant digit. Since  is before
is before  in the original array, and the numbers end in the same digit, they remain in the same relative order after the first pass. Then, we sort the array on the middle digit, and finally, on the most significant one.
in the original array, and the numbers end in the same digit, they remain in the same relative order after the first pass. Then, we sort the array on the middle digit, and finally, on the most significant one.
3.2. Complexity of Radix Sort
Assuming that the numbers have  digits (
digits ( ), Radix Sort loops times over . If the stable sorting algorithm it uses has the complexity
), Radix Sort loops times over . If the stable sorting algorithm it uses has the complexity  , then the time complexity of Radix Sort will be
, then the time complexity of Radix Sort will be  .
.
In particular, Counting Sort is a linear-time non-comparison sorting algorithm. With it, Radix Sort’s complexity becomes  , and if is a constant, the algorithm runs in
, and if is a constant, the algorithm runs in  time.
time.
3.3. Pseudocode
Here’s the pseudocode of Radix Sort:

3.4. Proof
We can prove the correctness of Radix Sort by induction on  . Our loop invariant is that the numbers we get by considering the
. Our loop invariant is that the numbers we get by considering the  least significant digits are sorted for each in the loop.
least significant digits are sorted for each in the loop.
Since the invariant trivially holds before the loop, let’s show that if it’s true at the start of an iteration , it’s also true at its end. So, if each ![a[j] = x_{d}^j x_{d-1}^j \ldots x_2^j x_1^j \equiv x_{d:1}^j](/wp-content/ql-cache/quicklatex.com-c636b75ffa4fedcac4de6f06acb96112_l3.svg "Rendered by QuickLaTeX.com") , before the -th iteration starts, we have:
, before the -th iteration starts, we have:
![\[x_{(i-1):1}^1 \leq x_{(i-1):1}^2 \leq \ldots \leq x_{(i-1):1}^n\]](/wp-content/ql-cache/quicklatex.com-c4ba7674665a2dfa06f72027b2e05f92_l3.svg "Rendered by QuickLaTeX.com")
Now, we sort on the -th least significant digit. All the numbers whose digit in question is 0 are before the numbers that have one as their -th least significant digit, and so on. As a result, we conclude that if  , then
, then  . So, to complete the proof, we need to show that the numbers with the same -th least significant digit are in the non-decreasing order.
. So, to complete the proof, we need to show that the numbers with the same -th least significant digit are in the non-decreasing order.
If  and
and  start with the same digit, and the former precedes the latter (
start with the same digit, and the former precedes the latter ( ), then
), then  preceded
preceded  before the -th loop. That follows from the stability of Counting Sort. Since we assume the invariant held before the -th loop, we know that
before the -th loop. That follows from the stability of Counting Sort. Since we assume the invariant held before the -th loop, we know that  . So, if , then
. So, if , then  .
.
At the end of the loop,  , so
, so ![a[j_1] \leq a[j_2]](/wp-content/ql-cache/quicklatex.com-ed82cb9dd06932e3cc5f9fb1a83fa455_l3.svg "Rendered by QuickLaTeX.com") if , which we wanted to prove.
if , which we wanted to prove.
4. Defining Digits in Radix Sort
We have some flexibility in defining the building blocks on which to sort. They don’t have to be digits. Instead, we can sort the numbers on groups made up from consecutive digits.
For example, we can break a  -digit number into five words containing two digits each:
-digit number into five words containing two digits each:
![\[x_9 x_8 \mid x_7 x_6 \mid x_5 x_4 \mid x_3 x_2 \mid x_1 x_0\]](/wp-content/ql-cache/quicklatex.com-9abefce1a476e38e9479066288b70ea7_l3.svg "Rendered by QuickLaTeX.com")
In general, if an integer has  bits, we can write as a
bits, we can write as a  -digit word by grouping
-digit word by grouping  bits at a time. Then, the complexity of Counting Sort is
bits at a time. Then, the complexity of Counting Sort is  , and since we call it times, the complexity of Radix Sort is
, and since we call it times, the complexity of Radix Sort is  . To get the best performance, we should set
. To get the best performance, we should set  to the value that minimizes
to the value that minimizes  .
.
If  , then
, then  since . So, in this case, setting
since . So, in this case, setting  minimizes the expression.
minimizes the expression.
Let’s suppose that  . If we choose
. If we choose  , the
, the  term increases faster than , so the runtime is
term increases faster than , so the runtime is  . Setting to
. Setting to  makes the complexity
makes the complexity  . Using
. Using  increases the fraction
increases the fraction  while
while  stays
stays  . So,
. So,  is the optimal choice if
is the optimal choice if  .
.
5. Radix Sort From the Most to the Least Significant Digit
We could sort the numbers on the digits from the most to the least significant one.
In the first pass, we sort on the most significant digit. Then, we recursively sort the sub-arrays containing the numbers starting with the same digit. In each call, we sort on the next less significant digit. When we sort on the last one, we stop.
Here’s the pseudocode:

However, the problem is that Counting Sort isn’t an in-place algorithm. Instead, it creates and returns a new array, that is, the input’s sorted permutation. So, recursive Radix Sort would reserve additional memory for  integers at each recursion level. Since the height of the recursive tree is
integers at each recursion level. Since the height of the recursive tree is  , this approach would take
, this approach would take  more memory than the first version of Radix Sort.
more memory than the first version of Radix Sort.
Even though that doesn’t change the algorithm’s space complexity if is a constant, it does affect memory consumption in practice. For that reason, recursive Radix Sort isn’t a good fit for applications with tight memory restrictions.
6. Sorting Non-integers
Can we apply this algorithm to non-integers? In general, the digits don’t have to be numerical. Any symbol (or a group thereof) can serve as a digit. However, we’d have to construct a mapping from actual to integer digits. The reason is that Counting Sort uses an integer array to count the elements.
Sometimes, Radix Sort isn’t applicable even if we design an integer mapping. For example, let input objects have fields, each with millions of possible values ( ). Although
). Although  , there are too many digits. Consequently, Counting Sort will perform poorly, taking way more memory than needed.
, there are too many digits. Consequently, Counting Sort will perform poorly, taking way more memory than needed.
We could use a hash map to reduce memory consumption, but we’d need to design a quality hash function. But, since hashed values would change over time, the worst-case complexity of hash lookup would be  . So, the approach would still be inefficient in practice.
. So, the approach would still be inefficient in practice.
7. Conclusion
In this article, we presented Radix Sort. It’s a stable linear-time sorting algorithm. Although Radix Sort has a linear time complexity, the multiplicative coefficient hiding under makes it less efficient than asymptotically worse comparison sorts in practice. Also, since Counting Sort isn’t an in-place algorithm, Radix Sort may take more memory than an  algorithm such as Quick Sort.
algorithm such as Quick Sort.