

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Database indexing is a crucial aspect of efficient data retrieval in modern databases. It plays a significant role in optimizing query performance and speeding up data retrieval operations.
In this tutorial, we’ll delve into the world of database indexing, exploring its inner workings, benefits, and limitations.
To understand indexing, let’s first take a quick look at databases. They are an organized way to reliably insert, store, update, retrieve and delete data. Historically, SQL databases have been the first, and they have stood the test of time as they are versatile and robust. The way they work is that information about all kinds of entities is stored in tables, each consisting of rows and columns:
In a table, data is organized into rows, with each row representing a record or entry. Columns, on the other hand, define the various attributes or properties of these records. To illustrate this, let’s consider a simple table with three columns: ID, e-mail, and name. Here’s an example:
| Primary Key | Unique Column | Non-unique Column |
|---|---|---|
| ID | name | |
| 1 | [email protected] | Michael |
| 2 | [email protected] | Bob |
| 3 | [email protected] | Michael |
For our purposes, a column can be one of 3 types:
Thus, each user is identified by his ID, has an e-mail address that is unique to him, and also has a name that other users can happen to share.
Let’s talk about indexing. When we index a column, we make searches faster, at the cost of administering an additional data structure behind the scenes.
This makes all searches significantly faster on large volumes of data.
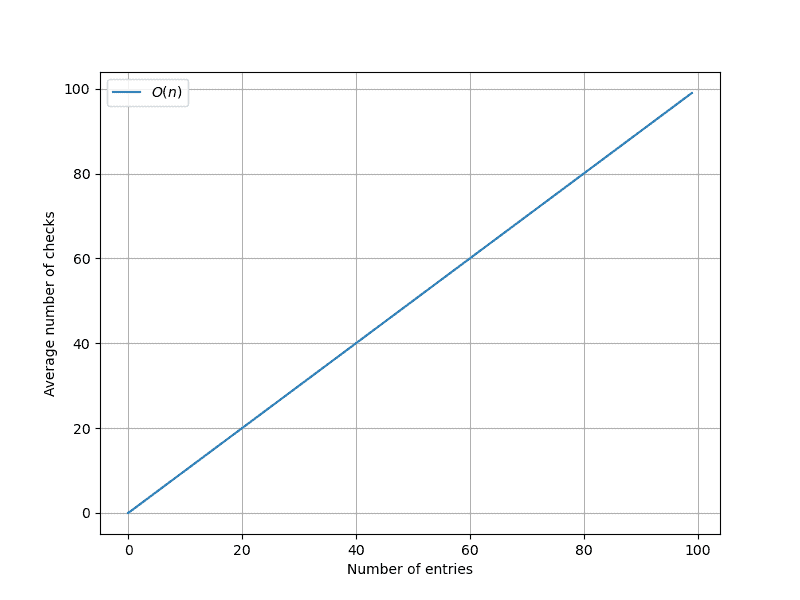
Let’s say we want to find users named “Michael”. Since multiple users can have this name, we need to go through all rows in the table in order to guarantee we find all of them.
If there are $n$ rows, we’ll need to go through $O(n)$ of them, on average, to find our answer.
Here’s a graph showing how fast we’ll find our item in a standard column:
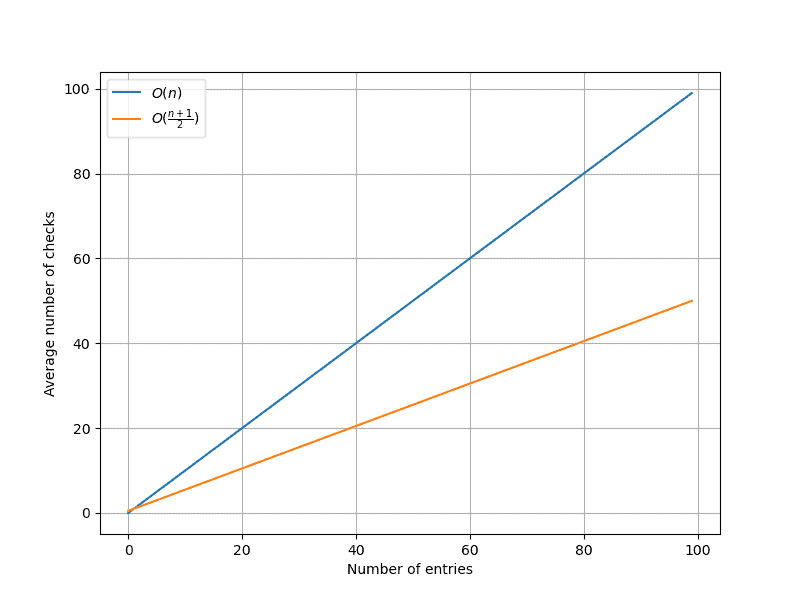
Let’s say we want to find the user with the “[email protected]” e-mail address. Since the e-mail is supposed to be unique, we can stop the search as soon as we find the row with the desired value.
If there are $n$ rows, we need to go through $O(\frac{n + 1}{2})$ of them, on average, to find our answer.
Here’s a graph showing how fast we’ll find our item in a unique column:
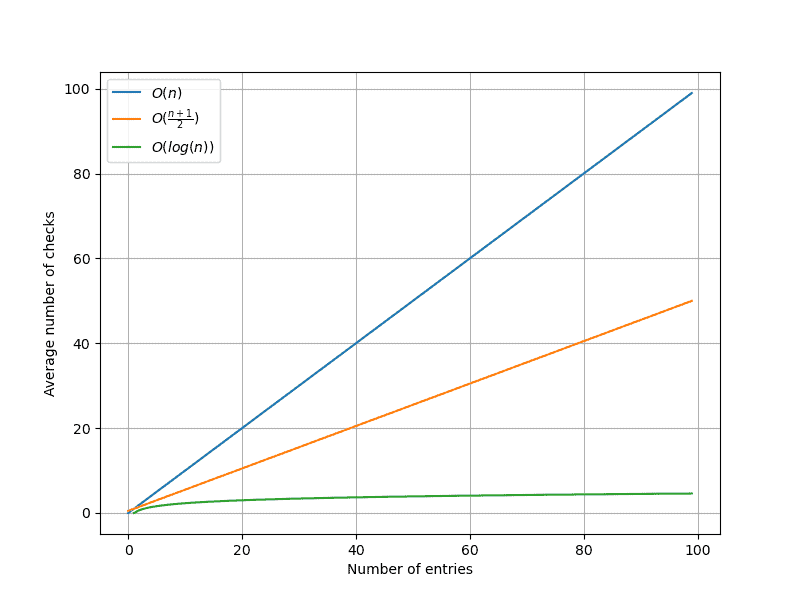
Let’s say we want to find a user with an ID equal to 4291. Simply because of the fact that the ID is a primary key, we are guaranteed significantly fewer search steps.
In fact, if there are $n$ rows, we’ll go through $O(log(n))$ of them, on average, to find our answer.
Finally, here’s a graph showing the performance of search with a primary key column:
To understand the magnitudes of these 3 scenarios, we can take a look at the following table:
| Size of table (entries) | O(n) | O((n+1)/2) | O(log(n)) |
|---|---|---|---|
| 10 | 10 | 6 | 4 |
| 1000 | 1000 | 501 | 10 |
| 100000 | 100000 | 50001 | 17 |
| 10000000 | 10000000 | 5000001 | 24 |
Not only is the O(log(n)) version always faster than the alternatives, but the difference between it and the other 2 becomes astronomical for large database sizes. This could be the difference between waiting seconds for a query instead of a couple of hours.
The idea of indexing is to enable searches through specific columns as fast as searches through the primary key.
Let’s say checking if an e-mail address exists in our database is an operation we do really often, we should then optimize it.
We don’t want to replace our primary key ID with the e-mail column as we want to allow users to change their e-mail addresses without losing their identity.
In this situation, the solution is creating a database index on the e-mail column.
The following table shows the link between the average number of checks we need to make and the column type used in the query:
| Size of table (entries) | Column | Unique column | Primary Key / Index |
|---|---|---|---|
| 10 | 10 | 6 | 4 |
| 1000 | 1000 | 501 | 10 |
| 100000 | 100000 | 50001 | 17 |
| 10000000 | 10000000 | 5000001 | 24 |
In this section, we’ll go over a couple of performance considerations that should be considered when deciding if an index is necessary for a specific column.
We’ll start from the following user table that initially has no indexes applied to it:
| ID | Name | Telephone | Address | Gender | |
|---|---|---|---|---|---|
| 1 | John Doe | 555-1234 | [email protected] | 123 Main St | Male |
| 2 | Jane Smith | 555-5678 | [email protected] | 456 Elm St | Female |
| 3 | Alex Johnson | 555-9876 | [email protected] | 789 Oak Ave | Male |
| 4 | Lisa Davis | 555-4321 | [email protected] | 321 Pine St | Female |
| 5 | Mark Wilson | 555-2468 | [email protected] | 654 Cedar Rd | Male |
| 6 | Emily Brown | 555-8642 | [email protected] | 987 Maple Ln | Female |
The primary purpose of indexing is vastly improved performance on database retrieval. There is, however, a trade-off that is made. While each query involving columns with indexes is way faster, each database insert, update or delete becomes slower. The more indexes we have, the more time it takes to modify entries, and more than that, each entry takes significantly more space.
Taking this into account, we could consider indexing the “Telephone” and “E-mail” columns, as these columns would be pretty useful at login time:
| ID | Name | Telephone | Address | Gender | |
|---|---|---|---|---|---|
| 1 | John Doe | 555-1234 | [email protected] | 123 Main St | Male |
| 2 | Jane Smith | 555-5678 | [email protected] | 456 Elm St | Female |
| 3 | Alex Johnson | 555-9876 | [email protected] | 789 Oak Ave | Male |
| 4 | Lisa Davis | 555-4321 | [email protected] | 321 Pine St | Female |
| 5 | Mark Wilson | 555-2468 | [email protected] | 654 Cedar Rd | Male |
| 6 | Emily Brown | 555-8642 | [email protected] | 987 Maple Ln | Female |
What we shouldn’t do is also index the “Name” and “Address” columns. This would be overkill, as finding a user fast by using his address or his name probably isn’t a realistic application need:
| ID | Name | Telephone | Address | Gender | |
|---|---|---|---|---|---|
| 1 | John Doe | 555-1234 | [email protected] | 123 Main St | Male |
| 2 | Jane Smith | 555-5678 | [email protected] | 456 Elm St | Female |
| 3 | Alex Johnson | 555-9876 | [email protected] | 789 Oak Ave | Male |
| 4 | Lisa Davis | 555-4321 | [email protected] | 321 Pine St | Female |
| 5 | Mark Wilson | 555-2468 | [email protected] | 654 Cedar Rd | Male |
| 6 | Emily Brown | 555-8642 | [email protected] | 987 Maple Ln | Female |
Columns with low cardinality, meaning they have a small number of distinct values compared to the total number of records, pose a challenge for indexing. In such cases, the index may not provide significant performance improvements as it would result in scanning a large portion of the table anyway. It’s important to assess the cardinality and uniqueness of columns before deciding whether to create an index.
As a result, indexing our table on the “Gender” column would be extremely ineffective, as it only has two possible values:
| ID | Name | Telephone | Address | Gender | |
|---|---|---|---|---|---|
| 1 | John Doe | 555-1234 | [email protected] | 123 Main St | Male |
| 2 | Jane Smith | 555-5678 | [email protected] | 456 Elm St | Female |
| 3 | Alex Johnson | 555-9876 | [email protected] | 789 Oak Ave | Male |
| 4 | Lisa Davis | 555-4321 | [email protected] | 321 Pine St | Female |
| 5 | Mark Wilson | 555-2468 | [email protected] | 654 Cedar Rd | Male |
| 6 | Emily Brown | 555-8642 | [email protected] | 987 Maple Ln | Female |
In this article, we discuss why database indexing is vital in optimizing query performance and enhancing the overall efficiency of data retrieval operations.
By creating efficient data structures and leveraging them during searches, indexing significantly reduces the time complexity of queries. It allows quick access to specific records, particularly in scenarios involving unique or primary key columns.