1. Overview
In this article, we are going to add Zipkin to our spring cloud project. Zipkin is an open-source project that provides mechanisms for sending, receiving, storing, and visualizing traces. This allows us to correlate activity between servers and get a much clearer picture of exactly what is happening in our services.
This article is not an introductory article to distributed tracing or spring cloud. If you would like more information about distributed tracing, read our introduction to spring sleuth.
Note: Zipkin project has deprecated the custom server. It is no longer possible to run a custom Zipkin server compatible with Spring Cloud or Spring Boot. The best approach to run a Zipkin server is inside a docker container.
In section 2, we describe how to setup Zipkin for a custom server build (deprecated)
In section 3, we describe the preferable default server build, setup, services configuration, and run process.
2. Zipkin Service With Custom Server Build
Our Zipkin service will serve as the store for all our spans. Each span is sent to this service and collected into traces for future identification.
2.1. Setup
We create a new Spring Boot project and add these dependencies to pom.xml:
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<scope>runtime</scope>
</dependency>
For reference: we can find the latest version on Maven Central (zipkin-server, zipkin-autoconfigure-ui). Versions of the dependencies are inherited from spring-boot-starter-parent.
2.2. Enabling Zipkin Server
To enable the Zipkin server, we must add some annotations to the main application class:
@SpringBootApplication
@EnableZipkinServer
public class ZipkinApplication {...}
The new annotation @EnableZipkinServer will set up this server to listen for incoming spans and act as our UI for querying.
2.3. Configuration
First, let’s create a file called bootstrap.properties in src/main/resources. Remember that this file is needed to fetch our configuration from the config server.
Let’s add these properties to it:
spring.cloud.config.name=zipkin
spring.cloud.config.discovery.service-id=config
spring.cloud.config.discovery.enabled=true
spring.cloud.config.username=configUser
spring.cloud.config.password=configPassword
eureka.client.serviceUrl.defaultZone=
http://discUser:discPassword@localhost:8082/eureka/
Now let’s add a configuration file to our config repo, located at c:\Users\{username}\ on Windows or /home/{username}/ on *nix.
In this directory let’s add a file named zipkin.properties and add these contents:
spring.application.name=zipkin
server.port=9411
eureka.client.region=default
eureka.client.registryFetchIntervalSeconds=5
logging.level.org.springframework.web=debug
Remember to commit the changes in this directory so that the config service will detect the changes and load the file.
2.4. Run
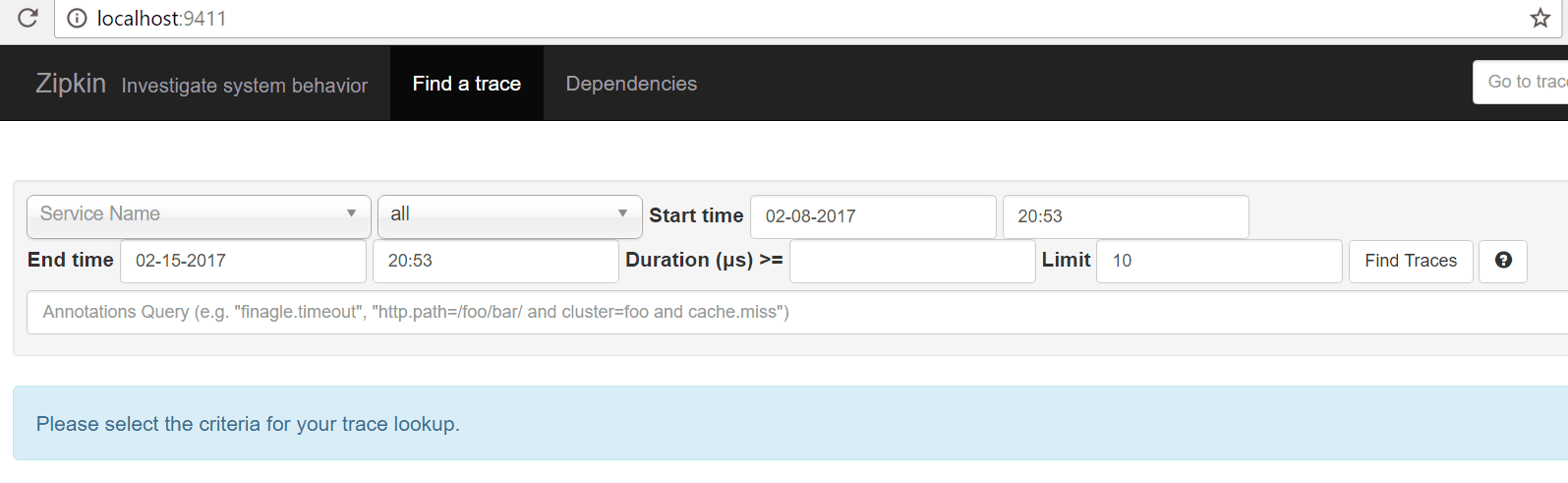
Now let’s run our application and navigate to http://localhost:9411. We should be greeted with Zipkin’s homepage:
Great! Now we are ready to add some dependencies and configurations to our services that we want to trace.
2.5. Services Configuration
The setup for the resource servers is pretty simple. In the following sections, we will detail how to set up the book-service. After that, we can configure the same for the rating-service and gateway-service.
2.5.1. Setup
To begin sending spans to our Zipkin server, we will add this dependency to our pom.xml file:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
2.5.3. Configuration
Now let’s add some configuration to our book-service.properties file in the config repository:
management.tracing.sampling.probability=1
Zipkin works by sampling actions on a server. By setting the management.tracing.sampling.probability to 1, we are setting the sampling rate to 100%.
3. Configuration With Default Server Build
As already stated, this is the suggested way to run Zipkin.
3.1. Zipkin Module Setup
In your IDE project, create a “Zipkin” folder and add a docker-compose.yml file with the contents:
version: "3.9"
services:
zipkin:
image: openzipkin/zipkin
ports:
- 9411:9411
Alternatively, check the official documentation here
3.2. Service Configuration
Service configuration is the same as in section 2.5 above.
3.3. Run
First, we start the Redis server, config, discovery, gateway, book, rating, and Zipkin docker image with “docker compose up -d“. Then we navigate to http://localhost:8080/book-service/books address. After that, we open a new tab and navigate to http://localhost:9411. On this page, we select book-service and press the ‘Find Traces’ button. We should see a trace appear in the search results. Finally, we can click that trace of opening it:

On the trace page, we can see the request broken down by service. The first two spans are created by the gateway, and the last is created by the book-service. This shows us how much time the request spent processing on the book-service, 18.379 ms, and on the gateway, 87.961 ms.
4. Conclusion
We have seen how easy it is to integrate Zipkin into our cloud application.
This gives us some much-needed insight into how communication travels through our application. As our application grows in complexity, Zipkin can provide us with much-needed information on where requests are spending their time. This can help us determine where things are slowing down and indicate what areas of our application need improvement.
The code backing this article is available on GitHub. Once you're
logged in as a Baeldung Pro Member, start learning and coding on the project.