1. Overview
This tutorial is a look at thread pools in Java. We’ll start with the different implementations in the standard Java library and then look at Google’s Guava library.
A quick and practical comparison between Threads and Virtual Threads in Java.
Learn how to use ExecutorService in various scenarios to wait for threads to finish their execution.
Brief intro to custom thread pools and their use in Java 8 parallel streams.
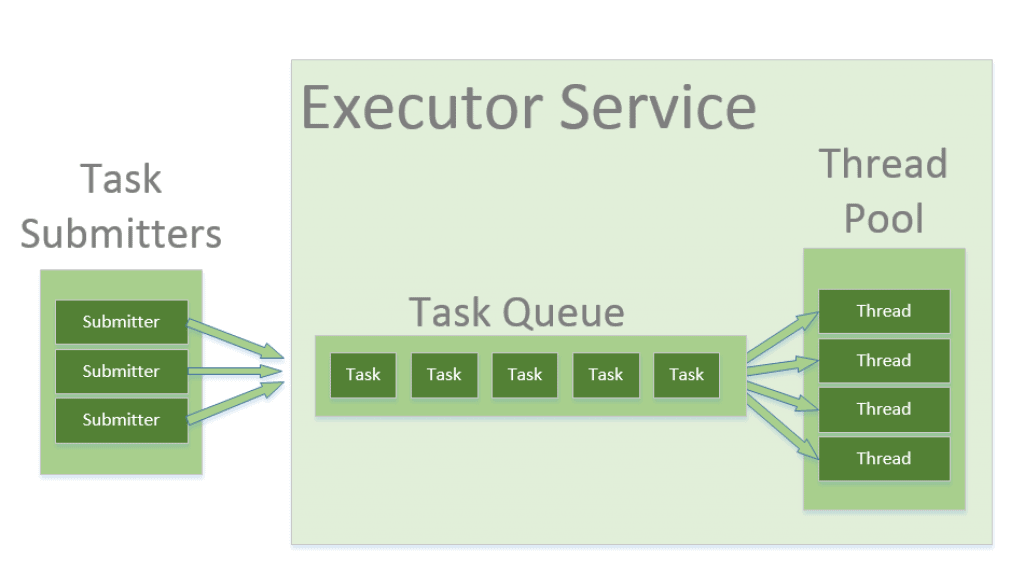
2. The Thread Pool
In Java, threads are mapped to system-level threads, which are the operating system’s resources. If we create threads uncontrollably, we may run out of these resources quickly.
The operating system does the context switching between threads as well — in order to emulate parallelism. A simplistic view is that the more threads we spawn, the less time each thread spends doing actual work.
The Thread Pool pattern helps to save resources in a multithreaded application and to contain the parallelism in certain predefined limits.
When we use a thread pool, we write our concurrent code in the form of parallel tasks and submit them for execution to an instance of a thread pool. This instance controls several re-used threads for executing these tasks.
The pattern allows us to control the number of threads the application creates and their life cycle. We’re also able to schedule tasks’ execution and keep incoming tasks in a queue.
3. Thread Pools in Java
3.1. Executors, Executor and ExecutorService
The Executors helper class contains several methods for the creation of preconfigured thread pool instances. Those classes are a good place to start. We can use them if we don’t need to apply any custom fine-tuning.
We use the Executor and ExecutorService interfaces to work with different thread pool implementations in Java. Usually, we should keep our code decoupled from the actual implementation of the thread pool and use these interfaces throughout our application.
3.1.1. Executor
The Executor interface has a single execute method to submit Runnable instances for execution.
Let’s look at a quick example of how to use the Executors API to acquire an Executor instance backed by a single thread pool and an unbounded queue for executing tasks sequentially.
Here, we run a single task that simply prints “Hello World“ on the screen. We’ll submit the task as a lambda (a Java 8 feature), which is inferred to be Runnable:
Executor executor = Executors.newSingleThreadExecutor();
executor.execute(() -> System.out.println("Hello World"));
3.1.2. ExecutorService
The ExecutorService interface contains a large number of methods to control the progress of the tasks and manage the termination of the service. Using this interface, we can submit the tasks for execution and also control their execution using the returned Future instance.
Now we’ll create an ExecutorService, submit a task and then use the returned Future‘s get method to wait until the submitted task finishes and the value is returned:
ExecutorService executorService = Executors.newFixedThreadPool(10);
Future<String> future = executorService.submit(() -> "Hello World");
// some operations
String result = future.get();
Of course, in a real-life scenario, we usually don’t want to call future.get() right away but defer calling it until we actually need the value of the computation.
Here, we overload the submit method to take either Runnable or Callable. Both of these are functional interfaces, and we can pass them as lambdas (starting with Java 8).
Runnable‘s single method does not throw an exception and does not return a value. The Callable interface may be more convenient, as it allows us to throw an exception and return a value.
Finally, to let the compiler infer the Callable type, simply return a value from the lambda.
For more examples of using the ExecutorService interface and futures, have a look at A Guide to the Java ExecutorService.
3.2. ThreadPoolExecutor
The ThreadPoolExecutor is an extensible thread pool implementation with lots of parameters and hooks for fine-tuning.
The main configuration parameters that we’ll discuss here are corePoolSize, maximumPoolSize and keepAliveTime.
The pool consists of a fixed number of core threads that are kept inside all the time. It also consists of some excessive threads that may be spawned and then terminated when they are no longer needed.
The corePoolSize parameter is the number of core threads that will be instantiated and kept in the pool. When a new task comes in, if all core threads are busy and the internal queue is full, the pool is allowed to grow up to maximumPoolSize.
The keepAliveTime parameter is the interval of time for which the excessive threads (instantiated in excess of the corePoolSize) are allowed to exist in the idle state. By default, the ThreadPoolExecutor only considers non-core threads for removal. In order to apply the same removal policy to core threads, we can use the allowCoreThreadTimeOut(true) method.
These parameters cover a wide range of use cases, but the most typical configurations are predefined in the Executors static methods.
3.2.1. newFixedThreadPool
Let’s look at an example. newFixedThreadPool method creates a ThreadPoolExecutor with equal corePoolSize and maximumPoolSize parameter values and a zero keepAliveTime. This means that the number of threads in this thread pool is always the same:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(2);
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(2, executor.getPoolSize());
assertEquals(1, executor.getQueue().size());
Here, we instantiate a ThreadPoolExecutor with a fixed thread count of 2. This means that if the number of simultaneously running tasks is always less than or equal to two, they get executed right away. Otherwise, some of these tasks may be put into a queue to wait for their turn.
We created three Callable tasks that imitate heavy work by sleeping for 1000 milliseconds. The first two tasks will be run at once, and the third one will have to wait in the queue. We can verify it by calling the getPoolSize() and getQueue().size() methods immediately after submitting the tasks.
3.2.2. Executors.newCachedThreadPool()
We can create another preconfigured ThreadPoolExecutor with the Executors.newCachedThreadPool() method. This method does not receive a number of threads at all. We set the corePoolSize to 0 and set the maximumPoolSize to Integer.MAX_VALUE. Finally, the keepAliveTime is 60 seconds:
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newCachedThreadPool();
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
executor.submit(() -> {
Thread.sleep(1000);
return null;
});
assertEquals(3, executor.getPoolSize());
assertEquals(0, executor.getQueue().size());
These parameter values mean that the cached thread pool may grow without bounds to accommodate any number of submitted tasks. But when the threads are not needed anymore, they will be disposed of after 60 seconds of inactivity. A typical use case is when we have a lot of short-living tasks in our application.
The queue size will always be zero because internally a SynchronousQueue instance is used. In a SynchronousQueue, pairs of insert and remove operations always occur simultaneously. So, the queue never actually contains anything.
3.2.3. Executors.newSingleThreadExecutor()
The Executors.newSingleThreadExecutor() API creates another typical form of ThreadPoolExecutor containing a single thread. The single thread executor is ideal for creating an event loop. The corePoolSize and maximumPoolSize parameters are equal to 1, and the keepAliveTime is 0.
Tasks in the above example will be run sequentially, so the flag value will be 2 after the task’s completion:
AtomicInteger counter = new AtomicInteger();
ExecutorService executor = Executors.newSingleThreadExecutor();
executor.submit(() -> {
counter.set(1);
});
executor.submit(() -> {
counter.compareAndSet(1, 2);
});
Additionally, this ThreadPoolExecutor is decorated with an immutable wrapper, so it can’t be reconfigured after creation. Note that this is also the reason we can’t cast it to a ThreadPoolExecutor.
3.3. ScheduledThreadPoolExecutor
The ScheduledThreadPoolExecutor extends the ThreadPoolExecutor class and also implements the ScheduledExecutorService interface with several additional methods:
- schedule method allows us to run a task once after a specified delay.
- scheduleAtFixedRate method allows us to run a task after a specified initial delay and then run it repeatedly with a certain period. The period argument is the time measured between the starting times of the tasks, so the execution rate is fixed.
- scheduleWithFixedDelay method is similar to scheduleAtFixedRate in that it repeatedly runs the given task, but the specified delay is measured between the end of the previous task and the start of the next. The execution rate may vary depending on the time it takes to run any given task.
We typically use the Executors.newScheduledThreadPool() method to create a ScheduledThreadPoolExecutor with a given corePoolSize, unbounded maximumPoolSize and zero keepAliveTime.
Here’s how to schedule a task for execution in 500 milliseconds:
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
executor.schedule(() -> {
System.out.println("Hello World");
}, 500, TimeUnit.MILLISECONDS);
The following code shows how to run a task after 500 milliseconds delay and then repeat it every 100 milliseconds. After scheduling the task, we wait until it fires three times using the CountDownLatch lock. Then we cancel it using the Future.cancel() method:
CountDownLatch lock = new CountDownLatch(3);
ScheduledExecutorService executor = Executors.newScheduledThreadPool(5);
ScheduledFuture<?> future = executor.scheduleAtFixedRate(() -> {
System.out.println("Hello World");
lock.countDown();
}, 500, 100, TimeUnit.MILLISECONDS);
lock.await(1000, TimeUnit.MILLISECONDS);
future.cancel(true);
3.4. ForkJoinPool
ForkJoinPool is the central part of the fork/join framework introduced in Java 7. It solves a common problem of spawning multiple tasks in recursive algorithms. We’ll run out of threads quickly by using a simple ThreadPoolExecutor, as every task or subtask requires its own thread to run.
In a fork/join framework, any task can spawn (fork) a number of subtasks and wait for their completion using the join method. The benefit of the fork/join framework is that it does not create a new thread for each task or subtask, instead implementing the work-stealing algorithm. This framework is thoroughly described in our Guide to the Fork/Join Framework in Java.
Let’s look at a simple example of using ForkJoinPool to traverse a tree of nodes and calculate the sum of all leaf values. Here’s a simple implementation of a tree consisting of a node, an int value and a set of child nodes:
static class TreeNode {
int value;
Set<TreeNode> children;
TreeNode(int value, TreeNode... children) {
this.value = value;
this.children = Sets.newHashSet(children);
}
}
Now if we want to sum all values in a tree in parallel, we need to implement a RecursiveTask<Integer> interface. Each task receives its own node and adds its value to the sum of values of its children. To calculate the sum of children values, task implementation does the following:
- streams the children set
- maps over this stream, creating a new CountingTask for each element
- runs each subtask by forking it
- collects the results by calling the join method on each forked task
- sums the results using the Collectors.summingInt collector
public static class CountingTask extends RecursiveTask<Integer> {
private final TreeNode node;
public CountingTask(TreeNode node) {
this.node = node;
}
@Override
protected Integer compute() {
return node.value + node.children.stream()
.map(childNode -> new CountingTask(childNode).fork())
.collect(Collectors.summingInt(ForkJoinTask::join));
}
}
The code to run the calculation on an actual tree is very simple:
TreeNode tree = new TreeNode(5,
new TreeNode(3), new TreeNode(2,
new TreeNode(2), new TreeNode(8)));
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
int sum = forkJoinPool.invoke(new CountingTask(tree));
4. Thread Pool’s Implementation in Guava
Guava is a popular Google library of utilities. It has many useful concurrency classes, including several handy implementations of ExecutorService. The implementing classes are not accessible for direct instantiation or subclassing, so the only entry point for creating their instances is the MoreExecutors helper class.
4.1. Adding Guava as a Maven Dependency
We add the following dependency to our Maven pom file to include the Guava library to our project. Find the latest version of Guava library in the Maven Central Repository:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.1.3-jre</version>
</dependency>
4.2. Direct Executor and Direct Executor Service
Sometimes we want to run the task either in the current thread or in a thread pool, depending on some conditions. We would prefer to use a single Executor interface and just switch the implementation. Although it’s not so hard to come up with an implementation of Executor or ExecutorService that runs the tasks in the current thread, this still requires writing some boilerplate code.
Gladly, Guava provides predefined instances for us.
Here’s an example that demonstrates the execution of a task in the same thread. Although the provided task sleeps for 500 milliseconds, it blocks the current thread, and the result is available immediately after the execute call is finished:
Executor executor = MoreExecutors.directExecutor();
AtomicBoolean executed = new AtomicBoolean();
executor.execute(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
executed.set(true);
});
assertTrue(executed.get());
The instance returned by the directExecutor() method is actually a static singleton, so using this method does not provide any overhead on object creation at all.
We should prefer this method to the MoreExecutors.newDirectExecutorService() because that API creates a full-fledged executor service implementation on every call.
4.3. Exiting Executor Services
Another common problem is shutting down the virtual machine while a thread pool is still running its tasks. Even with a cancellation mechanism in place, there is no guarantee that the tasks will behave nicely and stop their work when the executor service shuts down. This may cause JVM to hang indefinitely while the tasks keep doing their work.
To solve this problem, Guava introduces a family of exiting executor services. They are based on daemon threads that terminate together with the JVM.
These services also add a shutdown hook with the Runtime.getRuntime().addShutdownHook() method and prevent the VM from terminating for a configured amount of time before giving up on hung tasks.
In the following example, we’re submitting the task that contains an infinite loop, but we use an exiting executor service with a configured time of 100 milliseconds to wait for the tasks upon VM termination.
ThreadPoolExecutor executor =
(ThreadPoolExecutor) Executors.newFixedThreadPool(5);
ExecutorService executorService =
MoreExecutors.getExitingExecutorService(executor,
100, TimeUnit.MILLISECONDS);
executorService.submit(() -> {
while (true) {
}
});
Without the exitingExecutorService in place, this task would cause the VM to hang indefinitely.
4.4. Listening Decorators
Listening decorators allow us to wrap the ExecutorService and receive ListenableFuture instances upon task submission instead of simple Future instances. The ListenableFuture interface extends Future and has a single additional method addListener. This method allows adding a listener that is called upon future completion.
We’ll rarely want to use ListenableFuture.addListener() method directly. But it is essential to most of the helper methods in the Futures utility class.
For instance, with the Futures.allAsList() method, we can combine several ListenableFuture instances in a single ListenableFuture that completes upon the successful completion of all the futures combined:
ExecutorService executorService = Executors.newCachedThreadPool();
ListeningExecutorService listeningExecutorService =
MoreExecutors.listeningDecorator(executorService);
ListenableFuture<String> future1 =
listeningExecutorService.submit(() -> "Hello");
ListenableFuture<String> future2 =
listeningExecutorService.submit(() -> "World");
String greeting = Futures.allAsList(future1, future2).get()
.stream()
.collect(Collectors.joining(" "));
assertEquals("Hello World", greeting);
5. Conclusion
In this article, we discussed the Thread Pool pattern and its implementations in the standard Java library and in Google’s Guava library.
The source code for the article is available over on GitHub.